
Fog computing is Cisco’s view on edge computing and an important evolution in, among others, the Internet of Things (IoT) and especially Industrial IoT or IIoT with many connected applications in Industry 4.0 and more.
As the term fog already suggests there is an important link between fog computing and cloud computing. It’s often called an extension of the cloud to where connected IoT ‘things’ are or in its broader scope of “the Cloud-to-Thing continuum” where data-producing sources are.

Fog computing has been evolving since its early days. As you’ll read and see below fog computing is seen as a necessity for IoT but also for 5G, embedded artificial intelligence (AI) and ‘advanced distributed and connected systems’.
Fog computing is designed to deal with the challenges of traditional cloud-based IoT systems in managing IoT data and data generated by sources along this cloud-to-thing continuum. It does so by decentralizing data analytics but also applications and management into the network with its distributed and federated compute model – in other words: in IoT at the edge.
Fog computing versus edge computing
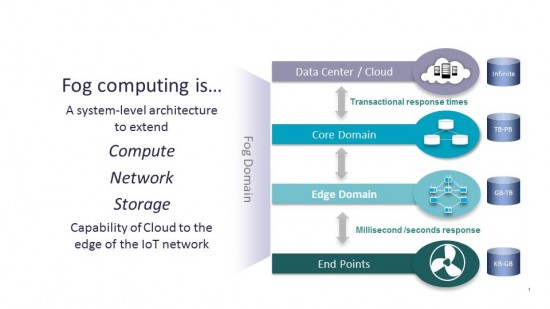
Fog computing, the term comes from Cisco, is not a network technology. It’s a hybrid system-level architecture approach whereby the possibilities of cloud computing and distributed processing and analytics power are brought to the edge of a network, in our scope the IoT network.
It does so in a different way than edge computing. In edge computing the aim is to bring the intelligence, analytics, computing, communications etc. very close and increasingly into devices such as programmable logic controllers and other, ever more powerful and smaller, devices at the edge and, after analysis etc., to the appropriate system or the cloud (or a data center).
Fog computing and edge computing are both about processing data closer to the source—a significant difference between both concerns the place where processing occurs. As fog computing is an extension of cloud computing to where data is created, it is located between the data center and the end equipment.
Fog computing is on a growth trajectory to play a crucial role in IoT, 5G and other advanced distributed and connected systems (Christian Renaud, 451 Research PR)
The processing, computing, storage, and network services in fog computing all are enabled between these both locations, typically at the LAN (local area network) level. You could say that in a sense, fog computing is somewhat of a gatekeeper to the cloud environment. In contrast, in edge computing, you’re closer to the endpoint in the end equipment/environment. This doesn’t mean that edge computing occurs on IoT devices, of course. Yet, the computation typically is only one or a few hops away, and the resources for processing, storage, etc. happen at the edge via micro data centers.
For those who want a really formal answer on what the difference between fog computing and edge computing is, NIST (more below) has an answer : “fog computing works with the cloud, whereas edge is defined by the exclusion of cloud and fog. Fog is hierarchical, where edge tends to be limited to a small number of peripheral layers. Moreover, in addition to computation, fog also addresses networking, storage, control and data-processing acceleration”.
Fog is hierarchical, where edge tends to be limited to a small number of peripheral layers
Fog computing and edge computing: same drivers
Both fog computing and edge computing have the same drivers: data processing and analysis at the edge. The reasons why, however are shifting.
According to IDC, 43 percent of all IoT data will be processed at the edge before being sent to a data center by 2019, further boosting fog computing and edge computing. And when looking at the impact of IoT on IT infrastructure, 451 Research sees that most organizations today process IoT workloads at the edge to enhance security, process real-time operational action triggers, and reduce IoT data storage and transport requirements. This is expected to change over time as big data and AI drive analysis at the edge with more heavy data processing at that edge.
In older research, from March 2017, Forrester Research stated that IoT will spawn a new infrastructure market with edge computing as the report name says. You can, among several others, download it via the Microsoft Azure resource center.
As Microsoft puts it on its “Edge computing: IoT will spawn a new infrastructure market” page: “a typical hierarchical network won’t be able to handle the huge increase in traffic IoT will bring”. It’s pretty much the same message everywhere albeit with slightly differing timeframes and of course keeping into account that all of this impacts both the evolutions in fog computing and in edge computing which are not one and the same as mentioned several times before (again, although many use them interchangeably given the overlapping IoT and other use case context, similar scope and, thus, by definition same markets leading the way with manufacturing first).
The role of fog nodes in fog computing
In fog computing the aim is to bring the data analysis and so forth as close as possible to the data source but in this case to fog nodes, fog aggregation nodes or, when decided so by the fog (IoT) application, to the cloud. That’s an essential difference with edge computing.
In other words: in fog computing the fog IoT application will decide what is the best place for data analysis, depending on the data, and then send it to that place.
Fog nodes may be either physical or virtual elements and are tightly coupled with the smart end-devices or access networks. Fog nodes typically provide some form of data management and communication service between the peripheral layer where smart end-devices reside and the Cloud. Fog nodes, especially virtual ones, also referred as cloudlets, can be federated to provide horizontal expansion of the functionality over disperse geolocations (NIST fog node definition in the 2017 NIST fog computing definition draft)
If the data is highly time-sensitive (typically below or even very far below a second) it is sent to the fog node which is closest to the data source for analysis. If it is less time-sensitive (typically seconds to minutes) it goes to a fog aggregation node and if it essentially can wait it goes to the cloud for, among others, big data analytics.
A fog node can take many shapes. As long as a device has the capacities (computing, storage and connectivity) to do what it needs to do at the edge, it can be a fog node. It could be a switch, a router, an industrial controller or even a video surveillance camera at some industrial location to name a few.
A fog node can also sit at many places: on the factory floor, on an oil rig or inside a car, for example, provided there is connectivity of course.
It’s clear that if a fog node needs to do what it needs to do in milliseconds or at least under a second that’s typically because an action, automated or otherwise needs to follow. And without connectivity that is pretty hard.
Fog computing in action
The actions which are taken based upon the analysis of (IoT) data in a fog node, if that’s where the fog application sent the data from the IoT sensors or IoT end devices to, can also take many shapes.
Just like transducers (sensors and actuators) it sets something in motion (output) based upon an input whereby the data from the input here is analyzed very rapidly. That output or action could be anything, ranging from automatically lowering temperature, changing parameters in a system whatsoever or closing/opening a valve or door to sounding an alarm, alerting an engineer via a message, triggering a change in some form of visualized/readable/viewable display/chart, for instance in a SCADA/HMI system and more.
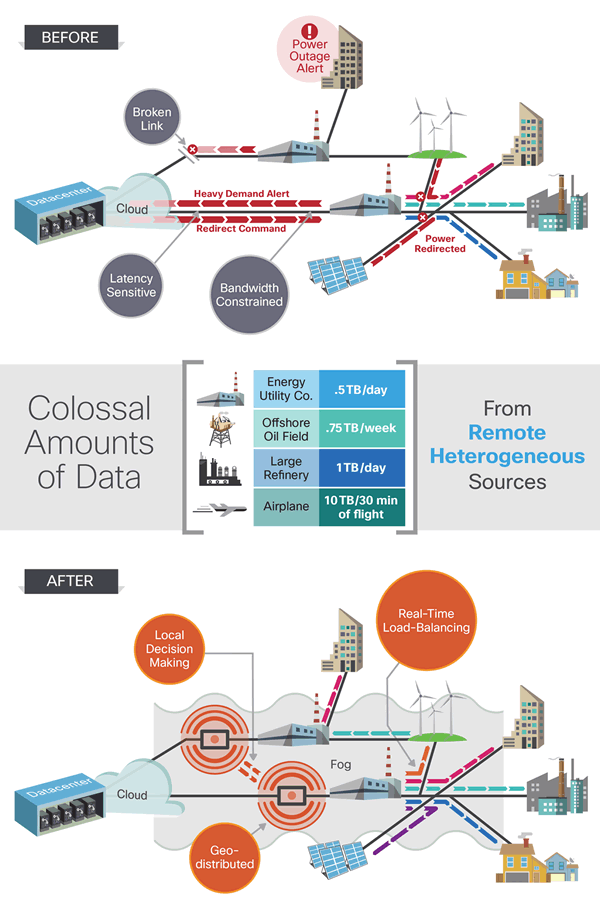
Simply said: instead of transporting all data over the network and then processing it, for instance in the cloud, some operations, mainly analytical, are performed close to the IoT device (where the data gets gathered), hence the edge of the network or the endpoint, and processes IoT data faster for a myriad of possible reasons where that speed matters but also without wasting bandwidth that can thus be saved.
There’s a bit more to it but in a nutshell that is what it does. Of course not all IoT data needs to be analyzed so fast that you need your analysis and computing power this close to the source and it isn’t just about bandwith and latency. It’s also about priorities.
Fog computing offers many benefits, such as: avoiding the costs of ever more bandwidth, solving high latency on the network, less bottlenecks, a reduced risk of connectivity failures, that higher speed of analysis and action, etc.
The OpenFog Consortium and OpenFog Reference Architecture
End 2015 a range of IoT leaders launched the OpenFog Consortium. The aim: accelerate the deployment of fog technologies through the development of an open architecture as the press release stated. The founding partners were not the smallest and included (obviously) Cisco, ARM, Dell, Intel, Microsoft and Princeton University.
Calling fog computing the distributed cloud technology that enables many of the real-time, data-intensive capabilities of the Internet of Things, 5G mobile technology, and artificial intelligence applications, Cisco’s Helder Antunes, who is chair of the Consortium wrote a blog post early 2018 looking back at some of the accomplishments of the OpenFog Consortium in 2017.
The major fog computing milestone no doubt was the release of the OpenFog Reference Architecture as depicted below, describing the various interrelationships of fog computing components. You can also learn more about that OpenFog Consortium Reference Architecture framework in the video at the bottom of this post.
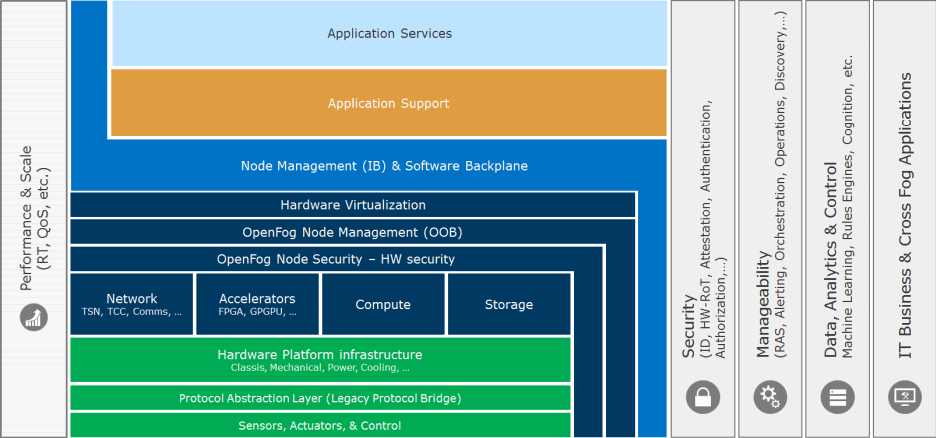
A second noteworthy fact for those interested in the usage of fog computing was the publication of the OpenFog Security Requirements and Approaches which expand on the security aspects of the OpenFog architecture and the security challenges in a distributed cloud environment and which you can check out in PDF here.
Also in October 2017 the Institute of Electrical and Electronics Engineers Standards Association said it will use the OpenFog Reference Architecture as the basis for its work on fog standards. As Helder Antunes writes the newly formed IEEE P1934 Standards Working Group on Fog Computing and Networking Architecture Framework expects to complete the first iteration of its work by April 2018. You can read more about the fog computing and networking standardization efforts/progress by the IEEE workgroup in our post on fog standardization.
The definition of fog computing – what is fog computing?
Here is how the consortium defines fog computing:
“Fog computing is a system-level horizontal architecture that distributes resources and services of computing, storage, control and networking anywhere along the continuum from Cloud to Things. By extending the cloud to be closer to the things that produce and act on IoT data, fog enables latency sensitive computing to be performed in proximity to the sensors, resulting in more efficient network bandwidth and more functional and efficient IoT solutions. Fog computing also offers greater business agility through deeper and faster insights, increased security and lower operating expenses”.
However, let’s also add that NIST, known from its work on among others cloud computing and its recently published draft on blockchain, also joined the fog computing evolution, seeking a formal definition of fog computing, just as it did before with the various cloud services and so forth.
With the comments closed on September 21, 2017, NIST Special Publication 800-191 (Draft) defines fog computing as “a horizontal, physical or virtual resource paradigm that resides between smart end-devices and traditional cloud or data centers. This paradigm supports vertically-isolated, latency-sensitive applications by providing ubiquitous, scalable, layered, federated, and distributed computing, storage, and network connectivity”.
The image from the NIST fog computing definition draft below shows fog computing in the broader scope of a cloud-based ecosystem serving smart end-devices.
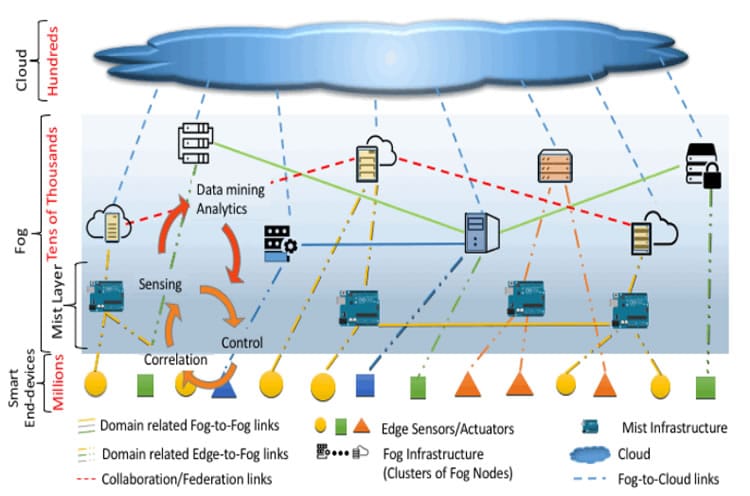
NIST also came up with a formal definition of a fog node it its draft document, defining fog nodes as intermediary compute elements of the smart end-devices access network that are situated between the cloud and the smart end-devices.
- From a service level model perspective, as fog computing is an extension of cloud computing, the NIST document took over well-known service models SaaS, PaaS and IaaS for fog computing too.
- From a node deployment model it identifies four type which also ring a few bells when comparing with cloud: private fog node, public fog node, hybrid fog node and community fog node.
The fog computing market: $18 billion by 2022
According to research, released end October 2017 at the occasion of the Fog World Congress, the fog computing market globally is expected to exceed $18 billion by 2022.
The OpenFog Consortium, which deems fog necessary for IoT, 5G and embedded artificial intelligence, commissioned 451 Research to dive deeper into the main markets for fog computing and networking, compare cloud versus on premise spend and break down the market into various segments (hardware, fog applications and services).
As the chart released at the occasion below shows, 51.6 percent of revenue goes to hardware, followed by fog applications (19.9 percent) and services (15.7 percent).
The biggest markets are transportation, industrial, energy/utilities and healthcare. Cloud revenue is expected to go up by 147 percent by 2022 and fog is expected to go into existing devices and software, working with new single-purpose fog nodes. Fog as a Service (FaaS) should double its growth between 2018 and 2022.

Fog computing IoT platforms
Just as edge computing does, fog computing plays an important role in the evolutions of the IoT platform market.
Industrial IoT platforms increasingly support edge capabilities and among the many IoT platform selection criteria these capabilities, as well as support for AI and other technologies, are far more important than before for the previously mentioned reasons (the drivers of both edge and fog computing).
Several vendors of IoT manufacturing platforms and IIoT platforms are part of the OpenFog Consortium and thus of the fog computing ecosystem. Examples of fog computing players include FogHorn Systems, fellow industry IoT middleware platform relayr and Nebbiolo Technologies. FogHorn and relayr are both tested and rated in MachNation’s IoT edge scorecard; relayr is also in MachNation’s IoT Application Enablement Platform scorecard and FogHorn Systems is a leading innovator in the manufacturing IoT platform assessment of ABI Research.
Back to that report of the OpenFog Consortium. While the main takeaways were shared at the Fog World Congress 2017 (the second one is organized early October 2018), an additional finding reported in the press release, on top of those mentioned, is that major market changes which drive the growth of fog include investment in the modernization of energy infrastructure, demographic shifts and regulations in healthcare and transportation.
Christian Renaud, research director, Internet of Things, 451 Research, and lead author of the report: “Through our extensive research, it’s clear that fog computing is on a growth trajectory to play a crucial role in IoT, 5G and other advanced distributed and connected systems. It’s not only a technology path to ensure the optimal performance of the cloud-to-things continuum, but it’s also the fuel that will drive new business value.”
The video that dives deeper into the OpenFog Reference Architecture and puts some other terms and pillars in perspective can be viewed on YouTube here.
Fog computing: verticals and use cases
Cisco’s Chuck Byers, co-chair of the Architecture Framework Working Group and Technical Committee of the OpenFog Consortium, mentioned vertical industries, use cases and applications in a blog post.
- Verticals range from transportation and logistics (the latter in the Logistics 4.0 scope), smart buildings and cities, IoT in healthcare and utilities/energy to agriculture, oil and gas, mining and also residential and consumer verticals. And of course smart manufacturing, the eternal number one industry from an IoT spending perspective.
- Use cases include smart highways, autonomous road vehicles, smart railways, maritime and drones (there are ample more) and applications obviously depend on the use cases within a vertical. In smart railways, for example think about Positive Train Control safety systems, scheduling and dispatch, energy/fuel optimization, passenger comfort and crew communications.
Fog computing: many benefits but not always the best solution
We’ll leave the last word, how else could we, to someone from Cisco who blogged at the occasion of the launch of the Fog Consortium and gave some examples of the possibilities of fog computing, going back to the roots and the first version of this overview.
We quote: “Fog computing can provide immense value across all industries. For example, it might take 12 days via satellite to transmit one day’s worth of data to the cloud from a remote oil rig. With fog computing the data is processed locally, and safety or equipment alerts can be acted upon immediately”.
Is fog always the best solution? No, there are circumstances where cloud computing is a better fit. It’s about striking the right balance and picking the best mix for the purpose of each different scenario. As it always is.
Fog computing is the system-level architecture that brings computing, storage, control, and networking functions closer to the data-producing sources along the cloud-to-thing continuum (OpenFog Consortium)
Moreover, in an often cited White Paper from, yes, Cisco, entitled “Fog Computing and the Internet of Things: Extend the Cloud to Where the Things Are” the authors offer an overview of when to consider fog computing as you can read in the paper (PDF opens) (e.g. when data is collected at the extreme edge such as in ships, roadways or, closer, factory floors; when there is high data generation across a large geopgraphic area and of course when analyzing this data and acting upon it needs to happen really fast).
Top image: Shutterstock – Copyright: phoenixman – All other images are the property of their respective mentioned owners.