
Traditionally, data professionals and information managers distinguish three types of data: structured data, unstructured data (mainly mentioned when people talk about big data) and, you guessed it, semi-structured data.
Some also talk about “quasi-structured”, “multi-structured” and “hybrid data” but in this article we’ll keep it simple. Although there are debates about the structure surrounding unstructured data and much more, it’s important to look at what these three types of data essentially mean, where they come from, how they are used and, most of all, how they can generate value. As the title already indicates, unstructured data is our major focus here.

Structured data versus unstructured data
There are really many definitions of unstructured data, structured data and all these other forms of data we just mentioned.
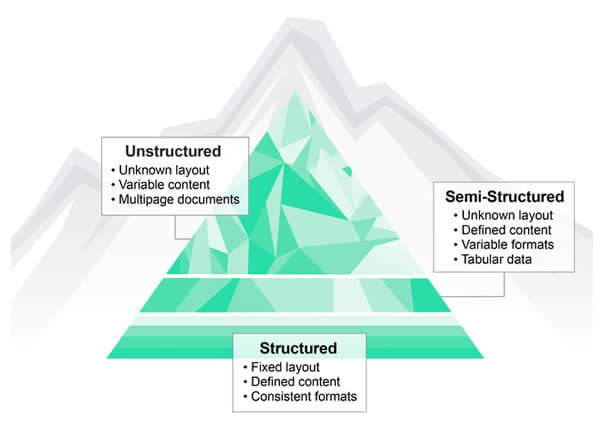
Structured data is traditionally defined as the data which you find in (relational) databases or in spreadsheets with a clearly defined format and structure. Data is easy to enter, store, retrieve, search and analyze. As an example think about a relational database or even an Excel file containing all your customer records.
Unstructured data is data that doesn’t sit in a database. Or better: it doesn’t follow the same data structure definitions and rules. This type of data traditionally was related with all sorts of files. Think about Word documents, images or digital audio files (there is textual and non-textual unstructured data). And then you have semi-structured data, sitting in-between both.
Now, why does this all matter and how does it impact your business? We’ll have to elaborate a bit more on the three types of data and put them in a somewhat historical perspective but first we take a look at the unstructured data challenge and opportunity, the reason why we wrote this to begin with.
We continue in a very basic way, before diving deeper into the “modern reality”.
The unstructured data and communications challenge: a little history
Let’s go back in time where we still worked with spreadsheets and very simple databases and data tools to conduct business.
You remember the example of a customer database (structured). There are other databases or ‘tables’ which also contain structured data regarding various aspects of your customers. And these are traditionally linked. You can have a list/table/database of sales transactions, which is linked with one listing your products and the database of customers, so you know what was purchased by whom. This is your basic traditional database approach in, let’s say 1990.
Now, various systems and processes exist in order to leverage such data sources to perform a specific function. Imagine we’re 1999, the Internet becomes very popular and you have a form on your website to offer customers support.
They have to fill in a few fields, entering data such as the invoice number which is also stored in your database of transactions. On top of that they can enter some more data, including, obviously the nature of their problem. All this data enters in any given system, again in a structured way, and you are able to get back to your customer with a full history of the purchase. We have much more in practice and in the various types of solutions used in such a context and the data can also be entered in another way, for instance, when your customers calls a contact center agent who can then enter the details of the call. The first CRM systems actually were nothing more than very static customer database systems (again, we’re in the nineties).
Unstructured data and the contact center
Fast-forward to 2016. The customer is omni-channel or channel-agnostic. He uses mobile devices and has numerous new ways to get in touch with your contact center.
He might still call or fill in a web form but he also sends emails (or even good old snail mail) and maybe text messages, Twitter support requests etc. He possibly interacts in real-time via webchat or videochat, the list goes on.
The problem with email, Twitter messages and so on is that they are essentially unstructured forms of communication. In other words: they contain information that can’t just be put in a structured format or a database for that matter.
On top of that your average customer today wants to be helped really fast, has high expectations and hates waiting and expects you to know everything you need to in order to help him out right here, right now.
The challenge is that most organizations aren’t able to do that, unless they have a really unified information approach and have connected all types of information.
Here is an example of what happens. A new customer has applied for, let’s say, a loan. He filled in some paperwork, possibly sent some documents, via post, via email, via a fax or digitally, when the document is scanned.
This information enters your organization. But it doesn’t enter your organization via the helpdesk or contact center. The customer’s request gets looked at follows the traditional path of approval. It does take some time and the customer gets a bit impatient. Who does he call? Not Ghostbusters. And not the people who deal with the loan request. No, he calls the contact center. Or he sends a mail, maybe to say he sent you a mail with an attachment, for instance a copy of his application form.
This is just one possible scenario but it shows the challenges. If your contact center has no insight in the processes which are happening in the back end, in this case, the status of the approval, he/she can’t help immediately. And if you have no unified approach with a capability to capture the important data hidden in the unstructured forms of communication (emails, Twitter messages) he/she is blocked as well. The result: a very frustrated customer.
This is one reason why a capacity to handle unstructured communications and data matters a lot, especially as these types of unstructured communications are growing (and we haven’t even touched upon the digitization of paperwork yet).
Unstructured data: the untapped majority of data which grows faster than any other type of data
There is a second reason why unstructured data matter a lot: by far the largest majority of information your organization holds is unstructured.
Organizations dispose of significant volumes of unstructured data. Estimates are that anywhere in-between 80 and 90 percent of data in an average organization is unstructured. Add to that the mountains of paper you still have and didn’t digitize yet, even it would be useful, and you see even more challenges and opportunities. We’ll zoom in on them further .
Obviously, unstructured data is not just found in a contact center context. In fact, unstructured data can sit anywhere in your company in any type of file in any format in your file system and storage hierarchies.

Unstructured data is, among others, omni-present in wealth management, insurance claims processing, medical files, account administration, etc. And as we have tackled earlier the way to deal with them is by using artificial intelligence.
Unstructured data and big data
Unstructured data is very important in a Big Data and analytics context
For starters, Big Data reignited the question of how to process all this unstructured data, moving it from more traditional areas such as research right into the center of business attention with, initially, a main focus on text analytics and/or content analytics.
In the end the accelerating growth of data volumes, sources and formats, mainly driven by unstructured data, is why IBM chose the path of cognitive computing with Watson and there is a strong growth of applications, using artificial intelligence techniques which were previously used in very specific areas but are now powering many technologies that are used to work with unstructured data, whether it concerns natural language, images or text.

A large portion of big data sources is unstructured. When IBM looked at the sources of Big Data with the help of the Said Business School at the University of Oxford end 2012, it found that companies were mainly looking at internal data sources and less than half were analyzing external data sources.
However, if you look at the graphic with the various types of internal and external data sources you’ll notice that all external data sources are unstructured (with social media taking the lead) and it isn’t any different when it boils down to internal data sources (log data, emails, etc.).
Unstructured data and communications: the need for artificial intelligence
Customer communications have changed dramatically with ever more unstructured communication channels and sources (email, social,….). There is a need to deal with all this unstructured communication and the resulting unstructured data and information.
Businesses need to know how to gather this information together and build from the knowledge contained within it.
Additionally there is a great deal of other important information hidden in this wealth of unstructured data. Only artificial intelligence can deal with all of this as unstructured data simply cannot be dealt with by a rule basis approach. Artificial intelligence takes away the need for rules.
It uses its intelligence to go beyond the basic information and works out content automatically, learns from human behavior and can also make predictions and forecasts.
Top image: Shutterstock – Copyright: Jirsak – All other images are the property of their respective mentioned owners.





