
What are data lakes and how are they used for big data analytics? A definition and description of data lakes, how they work and what are their benefits, drivers and disadvantages, including data lake market forecasts and trends 2020-2025.
To make a big data project succeed you need at least two things: knowing what (blended) actionable data you need for your desired outcomes and getting the right data to analyze and leverage in order to achieve those outcomes.

That much seems obvious. However, as you know we have ever more data coming from ever more sources and in ever more forms and shapes. Big data indeed. As you also know this volume of data, nor the variety and so forth are about to decline any time soon. Well on the contrary.
- Data lakes as a way to end data silos in a data deluge
- Data lakes are storage repositories with an analytics and action purpose
- Bottom-up data analytics: ingestion to fill up the data lake
- The usage of data lakes: storage, analytics, visualization and action
- Why data lakes? The benefits
- Data lake challenges, risks and evolutions
- The size of big data lakes
- Making sure data lakes don’t turn into data swamps
- The changing data lake approach – cloud, agile, analytics, value and AI/ML
- The data lake market 2020 – 2025
Data lakes as a way to end data silos in a data deluge
Just look at IoT (Internet of Things) where mainly the Industrial Internet of Things is poised to grow fast the coming years.
A data lake is a place to put all the data enterprises (may) want to gather, store, analyze and turn into insights and action, including structured, semi-structured and unstructured data
And with that growth indeed comes more data or better: data is what we are after with the Internet of Things, in order to gain big insights and drive relevant actions and operations to achieve whatever outcome: big data analytics with a purpose; smart data for smart applications – and inevitably artificial intelligence to make sense of all that data.
Traditionally data has been residing in silos across the organization and the ecosystem in which it operations (external data). That’s a challenge: you can’t combine the right data to succeed in a big data project if that data is a bit everywhere in and out of the cloud.
This is, among others, where the idea – and reality – of (big) data lakes comes from. As a concept, the data lake was promoted by James Dixon, who was CTO at Pentaho and saw it as a better repository alternative for the big data reality than a data mart or data warehouse.
Here is how Dixon defined or explained the data lake in 2011: “If you think of a datamart as a store of bottled water – cleansed and packaged and structured for easy consumption – the data lake is a large body of water in a more natural state. The contents of the data lake stream in from a source to fill the lake, and various users of the lake can come to examine, dive in, or take samples”.
Data lakes are storage repositories with an analytics and action purpose
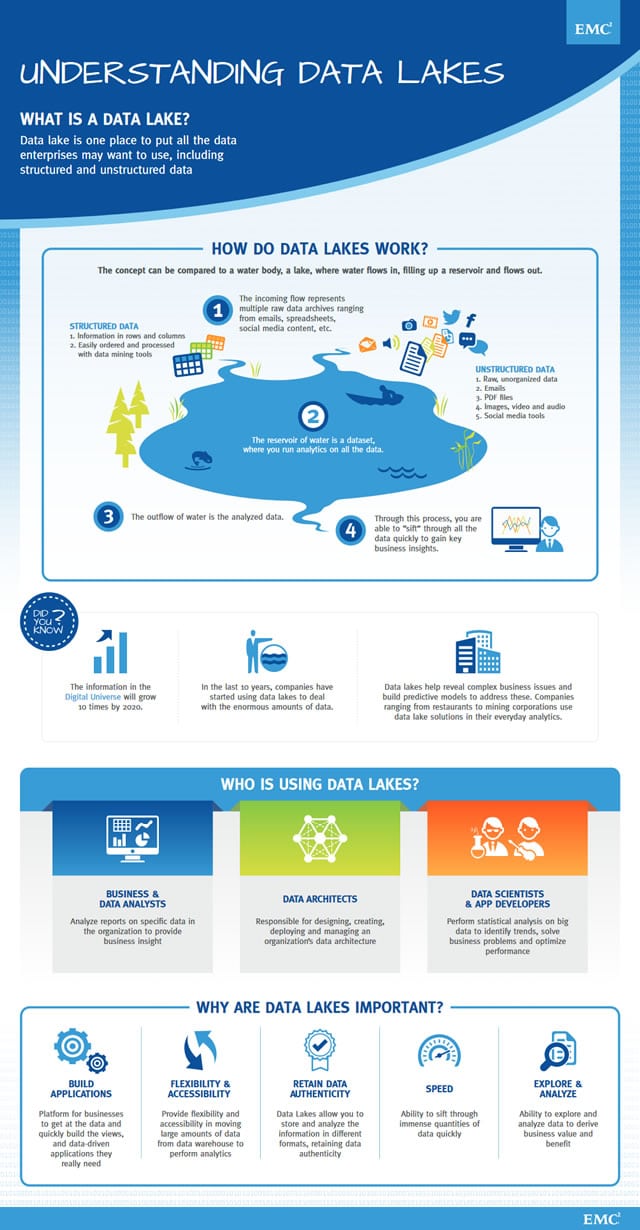
You can see a data lake indeed a bit like a lake, without the swans and the water. OK, that doesn’t look like a lake. But you get the idea: a big data lake in essence is a storage repository containing loads of data in their raw, native format.
Traditional data management approaches aren’t fit (or require a lot of money) to handle big data and big data analytics. With big data analytics essentially we want to find correlations between different data sets which need to be combined in order to achieve our business outcome. And if these data sets sit in entirely different systems, that’s virtually impossible.
An example of such a goal could be to combine data regarding a customer from one source with data from other sources and even seemingly unrelated data (for instance, traffic data, weather data, data on customers that seem non-related to our business) to act upon them to enhance the customer experience, come up with new services or simply sell more.
Bottom-up data analytics: ingestion to fill up the data lake
What does all this have to do with a data lake? Well, big data lakes are one of two information management approaches for analytics.
The first one is top-down (data warehousing), the second one is bottom-up, the data lake, the topic we’re covering here. To make this more tangible, let’s go back to the image of a real lake. A lake doesn’t just get filled like that. Usually there are rivers or smaller streams that bring water to it.
Data lakes are designed for big data analytics and to solve the data silo challenge in big data
In a data lake the same happens. This is also known as the ingestion of data, regardless of source or structure. We collect all the data we need to reach our goal through the mentioned data analytics.
These ‘streams’ of data come in several formats: structured data (simply said, data from a traditional relational database or even spreadsheet: rows and columns), unstructured data (social, video, email, text,…), data from all sorts of logs (e.g weblogs, clickstream analysis,…), XML, machine-to-machine, IoT and sensor data, you name it (logs and XML are also called semi-structured data).
They also involve various types of data from a contextual perspective: customer data, data from line-of-business applications, sales data, etc. (entered in the data lake via APIs). And, obviously we increasingly have external data (sources) which we want to leverage in order to achieve our goals.
The usage of data lakes: storage, analytics, visualization and action
All this data, as far as it makes or could make sense, gets stored in the data lake while it also keeps coming in, via Application Interface Protocols (APIs), feeding data from all sorts of applications and systems, or via batch processes.
The storage dimension is the second big piece (ingestion being the first one). And in the big data lake approach this de facto means that there are no silos. This, in consequence, means that we are ready to start the interesting work: big data analytics.
To go back to our example of combining data sets which sometimes seem to be non-related we can for instance detect patterns (using artificial intelligence) between purchasing behavior and weather patterns, between customer data from one source and customer data from another, between traffic data and pollution data, the list goes on. We try to keep it simple. What can you do with these patterns? A lot as you can imagine and ample big data usage examples in real life show, that’s where your business or other objective comes in.
Obviously analyzing is not enough. You also need to visualize, understand and act upon what you have analyzed. Or as the infographic from EMC on how data lakes work below puts it: the outflow of the water is the analyzed data, which then leads to action which leads to business insights. It’s indeed our good old
Why data lakes? The benefits
As said there are traditionally two information management approaches for analytics. Why are data lakes (the bottom-up approach) popular for data analytics?
There are different reasons. First, it’s important to understand that our image of a data lake as lake isn’t entirely correct, it’s not just some bottom-up big chaotic data swamp (although it can become one) and there are quite some technologies, protocols and so forth involved. To use the image of the streams going into the lake: there are filters in place before the water actually goes into the lake.
The historical legacy data architecture challenge
Some reasons why data lakes are more popular are historical.
Traditional legacy data systems are not that open, to say the least, if you want to start integrating, adding and blending data together to analyze and act. Analytics with traditional data architectures weren’t that obvious nor cheap either (with the need for additional tools, depending on the software). Moreover, they weren’t built with all the new and emerging (external) data sources which we typically see in big data in mind.
Faster big data analytics as a driver of data lake adoption
Another important reason to use data lakes is the fact that big data analytics can be done faster.
In fact, data lakes are designed for big data analytics if you want and, more important than ever, for real-time actions based on real-time analytics. Data lakes are fit to leverage big quantities of data in a consistent way with algorithms to drive (real-time) analytics with fast data.
Mixing and converging data: structured and unstructured in one data lake
A benefit we more or less already mentioned is the possibility to acquire, blend, integrate and converge all types of data, regardless of sources and format.
Hadoop, one of the data lake architectures, can also deal with structured data on top of the main chunk of data: the previously mentioned unstructured data coming from social data, logs and so forth. On a side note: unstructured data is the fastest growing form of all data (even if structured data keeps growing too) and is predicted to reach about 90 percent of all data.
Moving data analytics to the source – the data lake and the edge
Then, there is the fact that moving large data sets back and forth isn’t exactly the smartest thing to do.
With big data lakes the applications are close to where the data resides. An interesting development in this sense is that you see the applications (or big data analytics) moving to the edge rather than to a storage repository to move even faster and take away the burden from networks, among others. This is the essence of edge computing in the scope of data analytics in the connected factory context of Industry 4.0 and the Industrial Internet.
Data lakes and flexibility: grow and scale as you go
Next, data lakes are highly scalable and flexible. That doesn’t need too much elaboration. The system and processes can easily be scaled to deal with ever more data.
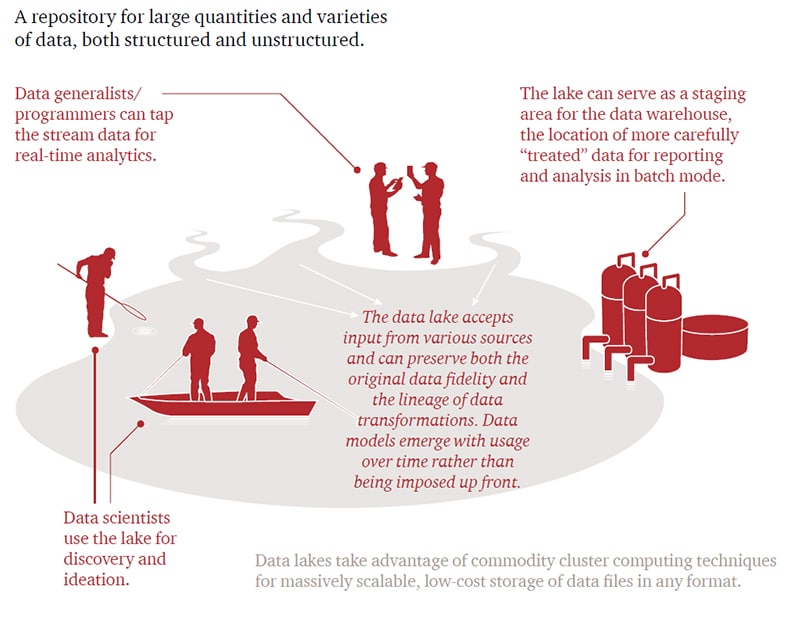
Saving enterprise data warehouse resources
A final benefit we mention is that, as the illustration from PwC above shows a data lake can serve as a staging area for the (enterprise) data warehouse (EDW).
It then is used to pass on relevant data only to the warehouse, whereby it can save EDW resources.
Data lake challenges, risks and evolutions
There are more benefits of big data lakes, yet as per usual we don’t want to get too technical. And, also as per usual, there are benefits, risks and challenges to address.
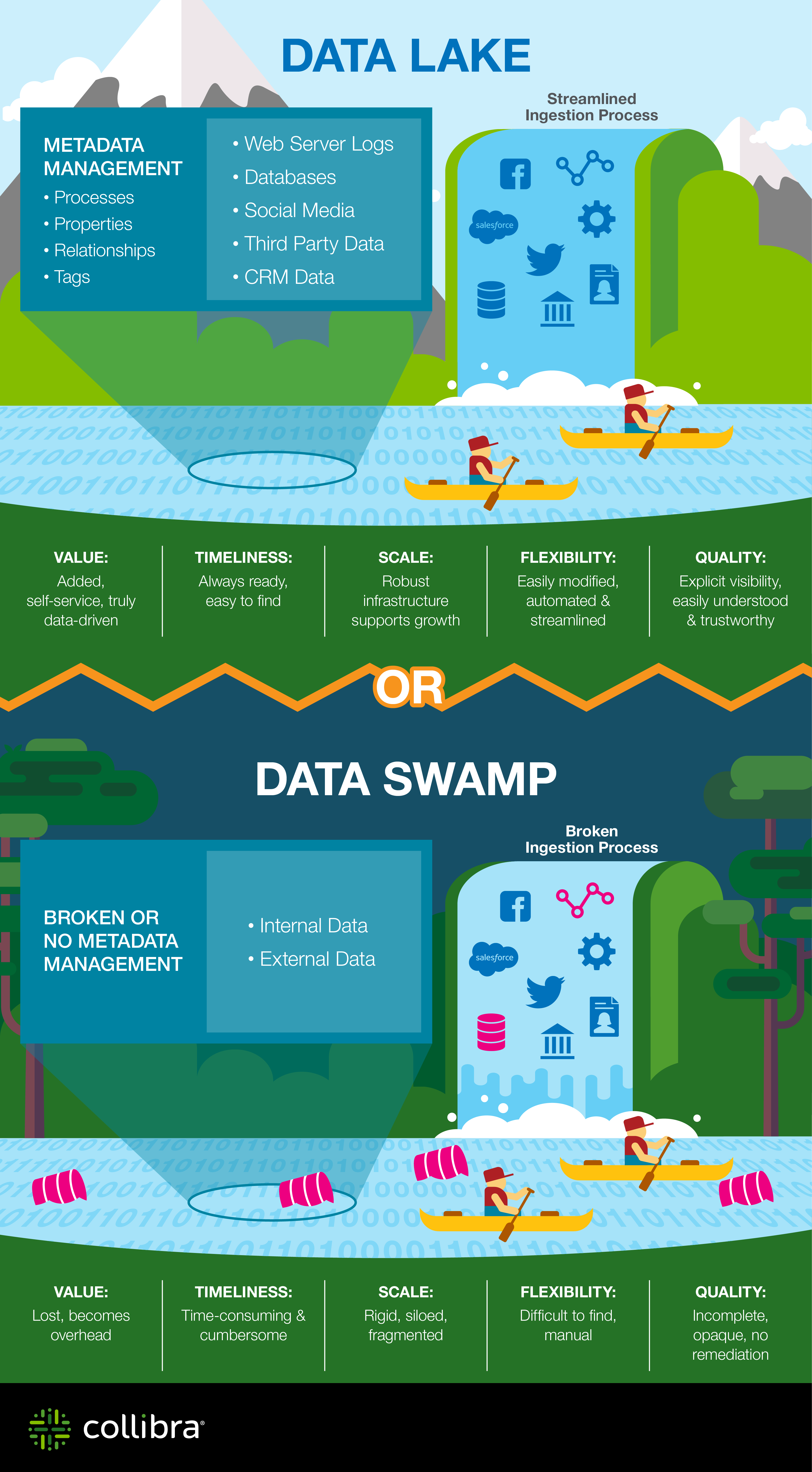
One of them is the mentioned risk that data lakes can become data swamps if not properly strategically designed with the necessary goals and cleaning in mind. This is also the reason why organizations move from the very traditional data lake approach to a goal-oriented and business-driven one.
Obviously, data lakes should be approached from a business-driven and strategic approach as such. However, historically they have often been seen from the rising data volume perspective and the notion that in the end all data have potential value.
Potential means in the future and, while that value is indeed, well, potential, quite some companies acted like data hoarders (which is by the way not uncommon in information management, it’s a key reason why there is still so much paper around and going paperless remains a pipe dream), without thinking too much about the data and metadata that really mattered (metadata management is an important element in a data lake context).
Moreover, there is the question if a data lake is needed for your organization and goals and, if so, if you can derive value from your data lake.
A 2015 survey by Gartner, showed that for several companies Hadoop (a leader for data lake architecture) was overkill and that skills gaps (to derive value from Hadoop) were the major inhibitor.
The size of big data lakes
Since big data volumes and usage keep growing with big data initiatives that are increasing in breadth, depth and inclusivity as Qubole puts in a blog, data lake sizes obviously keep growing too.
The blog post, which announces the 2018 Big Data Trends and Challenges report by Dimensional Research (sponsored by Qubole) points out that the percentage of organizations with average data lake sizes over 100 Terabytes has grown from 36% in 2017 to 44% in 2018 (an increase of 22% in one year). This trend will only continue and is just one of many drivers of the shift of big data processing to the cloud.
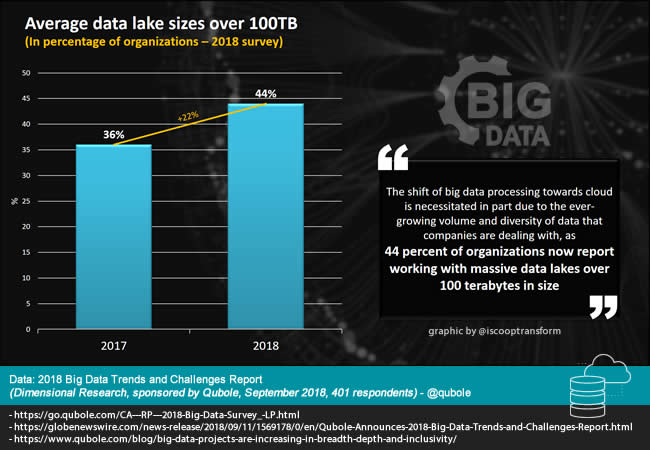
Qubole: “The shift towards cloud is necessitated in part due to the ever-growing volume and diversity of data that companies are dealing with, as 44 percent of organizations now report working with massive data lakes over 100 terabytes in size”.
The report, which you can download here, reminds that forecasts call for future datasets that far exceed the sizes of today’s big data repositories.
The eternal challenge however remains: how to get value out of all that data. Decisions and actions indeed – that is and should be a key driver in how the market evolves.
Making sure data lakes don’t turn into data swamps
Let’s take a somewhat deeper look at those data swamps. As said, in the early days of data lakes, the focus was a lot on the volume aspect of big data and many organizations de facto used data lakes as a place to dump data.
This led to that phenomenon of data swamps – and similar terms essentially expressing that instead of nice clean data lakes with the proper ways needed to keep them clean were turning into data cesspools. Analysts (mainly Gartner) quickly pointed out that data lake initiatives failed.
Research by Eckerson Group shows that enterprises today are letting their business users take advantage of their data lakes
Even today we still hear organizations asking the wrong questions like ‘should I replace my data warehouse by a data lake?’ to mention just one. Data lakes are often still compared to data warehouses (and data marts). While understanding the differences is important the question what to use and when isn’t that much about the best technologies and, as the consultant tends to say, what you need really depends.
The goals we aim to solve with data repositories and the data analytics and business intelligence environments they fit in are the same old questions regarding, among others,
- what we want to achieve with our data,
- how we get more value out of that data (including external data),
- what use cases we see to monetize data through advanced analytics,
- what skills we have/need,
- how data-driven our business is (which is typically a continuum whereby we move from ‘less’ to ‘more’ unless of course we’re one of those few organizations that exist because of data to begin with),
- where we are today (including skills and culture) and, certainly in some industries more than in others,
- what we need to take into account regarding sensitive data in a scope of regulations (e.g. financial services),
- etc.
When the case for a data lake becomes clear it’s not that hard to make sure it doesn’t turn into a data swamp. That discussion has been long held and we know that data lakes need a bit more strategy and attention than some perhaps might have thought in those days of ‘throw it all in the pool, we’ll see’. The graphic below gives a few reasons why data lakes turn into data swamps and (thus) what to take into account.
The changing data lake approach – cloud, agile, analytics, value and AI/ML
The data lake landscape of course isn’t what it used to be either as previously touched upon. Whereas in the early days data lakes were essentially about adding Hadoop with all the on-premises stuff still existing, today organizations go more for data lakes in the cloud as mentioned in the small summary of the Qubole report above.
Initially, a data lake is for power users who have the skills and ability to go swimming through this lake, finding the nuggets they want, and then be able to process that using schema-on-read technologies. Fortunately, SQL is making inroads into the data lake, and we’re starting to learn how to model different islands within it, giving users direct access to data in the data lake (Wayne Eckerson, Eckerson Group, 2018)
Attention though: for now the majority of organizations still use Hadoop and on-premises is still in the lead as you can also see the key takeaways from 2018 research by Eckerson Group for Arcadia Data which you can download here and was presented in a webinar “Are Data Lakes for Business Users?” that you can check out at the bottom of this article.
The research gives a good overview of some of the more recent evolutions regarding data lakes and also dispels some data lake myths. Also make sure you watch the short interview with Wayne Eckerson who weighed in on the matter, among others pointing to the two roads of various BI vendors, essentially 1) enabling to query data directly or 2) pulling the data into a specialized database (some do both), which each come with their benefits and downsides (also see the quote above on SQL making inroads).
Depending on the source the majority is still on premises, but cloud increases fast as it does overall in business. The big three players have solid offerings. It’s clear that the future of data lakes spells cloud, although again there will be exceptions for some industries because of, among others, regulatory issues and a traditionally more careful approach towards – certainly public – cloud in general.

Organizations obviously also have learned from mistakes made in the past and, finally, the focus is much more on outcomes and value with artificial intelligence and machine learning becoming far more important, along with the need for near real-time analytics, advanced analytics and visualization.
We also see a shift in business intelligence towards in-data-lake BI solutions. Simply put and to summarize: the data lake landscape evolves fast, the essence is still about turning data into value and the means to do this better, the solutions that exists since those early days, ample trends on the technology front and the lessons learned, make it hard to compare the past of data lakes with their present, let alone future, a future that looks pretty bright with many organizations indicating they have plans to deploy a data lake, with a shift to the cloud.
Finally, let’s not forget that when data lakes became popular, big data still was a buzzword. These days are – more or less – over or, at least, big data has become ubiquitous. Big data is data and the question is what to do with it. Although that remains the question most professionals still get from organizations (‘what do I do with all that data to benefit from it?’) overall data maturity has increased and new generations of experts know that big data analytics is the crux of the matter to reap value and that you don’t approach data the same way as you used to in the days of traditional data warehouses – the mindset and culture regarding leveraging big data has evolved and continues to.
The data lake market 2020 – 2025
Forecasts regarding the growth of the data lake market for the coming years vary, yet they all show a double-digit compound annual growth rate.
With the shift towards cloud-based data platforms to manage and mitigate data issues expected to offer opportunities for data lake solution adoption further, MarketsandMarkets expects the global data lake market to grow at a CAGR of 20.6 percent until 2024.
The major growth factors of the data lake market include the increasing need to extract in-depth insights from growing volumes of data to gain a competitive advantage in the market, and simplified access to organizational data from departmental silos, mainframe, and legacy systems.
According to the research report, announced in early 2020, the global data lake market size is forecasted to reach $20.1 billion by 2024, coming from an estimated $7.9 billion in 2019.
Another report, by Mordor Intelligence, values the data lake market in 2019 at $3.74 billion, expecting it to reach $17.6 billion by 2025 or a CAGR of 29.9 percent over the forecast period 2020-2025.
Obviously, it’s hard to compare various forecasts if you haven’t seen the methodologies and precise scope but recent and older reports alike show a CAGR of around 25 percent.
The MarketsandMarkets report announcement states that, from a business function perspective, operations will be the fastest grower in terms of data lake solution adoption and deployment growth while marketing is expected to keep holding the largest market share. From an industry perspective, the highest growth is expected to come from the healthcare and life sciences segment during the forecast period, “due to the existence of a large patient pool, especially in large-sized hospitals specializing in various streams of medicine.”
Most data lake market revenue will come from North America with high adoption in Banking, Financial Services, and Insurance (BFSI). More about the report here.
The second report also sees the highest adoption of data lakes in North America. Globally, it expects the usage by the banking sector to grow significantly. On top of financial services, the announcement also focuses on the need of data lakes in the context of smart meter projects in the US and Canada.
Top image: Shutterstock – Copyright: GarryKillian – All other images are the property of their respective mentioned owners.





