
Organizations across the globe are speeding up digitization and digital transformation efforts, partially driven by the consequences of the health crisis. The pandemic also has an impact on some areas of data management as data creation skyrocketed. Data storage deserves more enterprise attention.
As digital adoption took a quantum leap, to paraphrase McKinsey, digitization in organizations accelerated by several years due to COVID-19. The precise number of years depends on the business area and source.

When people are at home, Internet traffic increases, as the data from Cisco in an article on digital transformation and COVID show. And an increase in traffic means more data. E-commerce soared, we adopted remote working or hybrid working, streaming volumes went up, classes went digital as schools closed, you can continue the list.
The increasing adoption of digital services for various purposes impacted the so-called datasphere and the volumes of big data pouring in from everywhere while the usage of cloud computing services accelerated across the board.
As described in our article on digital transformation as a new normal, organizations switched to digitization and swiftly adapted digital transformation strategies to accommodate changing needs and offer digital services and channels. Again more data. The impact of the pandemic on data creation and replication was more significant than that of consumers.
The amount of digital data created over the next five years will be greater than twice the amount of data created since the advent of digital storage.
The impact of the pandemic on the growth of the DataSphere and StorageSphere
Quite some changes are poised to last. This inevitably means that the volumes of data generated will also grow faster than we previously expected (and forecasts were already impressive). Add the plans of governments to boost their digital economies and industrial transformations (Industry 4.0 and now also Industry 5.0 in some regions), and you know what’s coming.
The impact of the pandemic on the creation, consumption, and storage of data clearly showed in an annual update of the DataSphere and StorageSphere forecasts from IDC.
In March 2021, the research firm announced that the amount of data created and replicated grew at an unusually high pace in 2020 due to the pandemic and a “dramatic increase in the number of people working, learning, and entertaining themselves from home.”
A total of 64.2ZB (zettabytes) of data was created or replicated in 2020. To put that in perspective: only two years earlier, in 2018, the ‘Data Age 2025’ research reported that the global datasphere had reached 33 zettabytes.
The creation of – ever more – data due to the pandemic doesn’t end with the health crisis. Many people across the globe started using digital tools (mainly SaaS cloud applications) and channels for purposes such as banking, videoconferencing, and entertainment. And many will continue to do so. Add all the other factors, including those where the pandemic has no direct impact (e.g., the arrival of 5G), and it seems that IDC’s prediction that the global datasphere might reach 175 zettabytes by 2025 isn’t far-fetched.
The implications will be felt everywhere: cloud, edge computing, digital economy, and indeed data and information management evolutions, a domain that’s changing fast (e.g., with DataOps) and in many aspects remains a struggle for businesses.
The data storage and retention challenge (ahead)
From a data management perspective, one area is quite interesting: data storage. Per IDC’s Dave Reinsel, “the amount of digital data created over the next five years will be greater than twice the amount of data created since the advent of digital storage.” “The question,” he adds: “how much of it should be stored?”
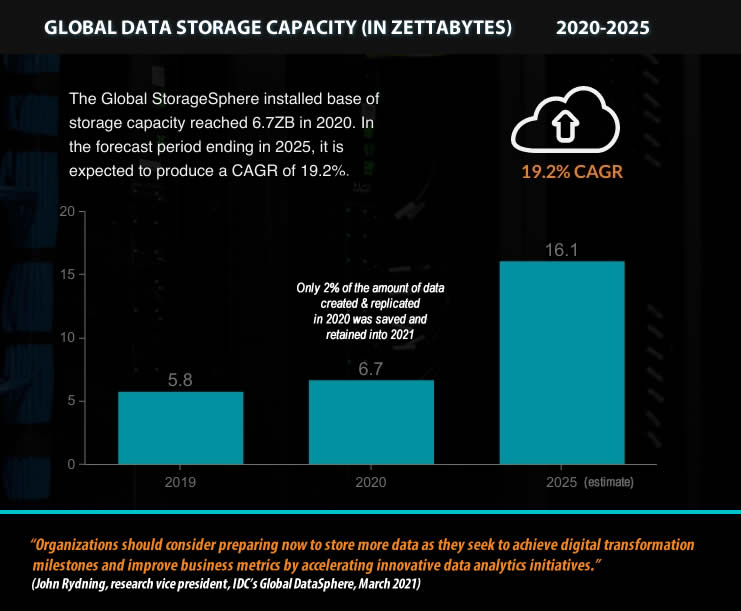
The question is all the more relevant because only 2 percent of the amount of data created and replicated in 2020 was saved and retained into 2021 per IDC’s annual DataSphere and StorageSphere forecasts. Moreover, IDC found that, while the global StorageSphere obviously continues to grow (an installed base of storage capacity of 6.7 zettabytes in 2020), it does so slower than the DataSphere. Simply put: we create, replicate, and consume more data but save less of the data we generate each year.
The difference is normal (not all data needs to be stored or kept), but it has become too big, and more attention for data storage is required. For IDC’s John Rydning, “organizations should consider preparing now to store more data as they seek to achieve digital transformation milestones and improve business metrics by accelerating innovative data analytics initiatives.” Do note that the enterprise DataSphere is forecast to grow two times faster than the consumer DataSphere, given the increasing role of the cloud in data storage and consumption.
Why should we store more of the data we create? IDC sees three reasons:
- data is vital to establish digital resiliency,
- data is essential for future innovation and transformation,
- data enables to monitor what needs to be monitored, such as the pulse of customers, to take action where needed.
While organizations with a data culture typically know this, the costs of storing more data and failure to leverage all that data (now) in a meaningful way, along with the ROI challenge in data analytics initiatives, are essential hurdles to store more data and retain it longer (which doesn’t equal data hoarding).
That’s partially a consequence of data management challenges and data skills, and it has an impact on how we look at big data and different means to leverage data. But that’s another story.
Fact is that we seem to store and retain less for business purposes such as innovation, resiliency, and customer experience optimization, even if only in a later stage. It seems time that organizations realize more data analytics with positive and clear ROI to change that.
Cloud and edge in data storage and creation
In the meantime, it’s clear: the pandemic accelerated growth of the DataSphere, and that continues to have an impact. But the StorageSphere, that’s another story and debate with work ahead as the DataSphere is on the verge of even more phenomenal growth.
IDC’s revised model now predicts that global data creation and replication (DataSphere) will experience a compound annual growth rate (CAGR) of 23% over the 2020-2025 period.
The expansion of the StorageSphere is forecast to result in a CAGR of 19.2% in the installed base of worldwide data storage capacity.
The fastest-growing data segment is IoT data, and data creation at the edge grows nearly twice as fast as that in the cloud. Yet, data creation in the cloud grows faster than the aggregate DataSphere (as it did before).
Cloud storage providers will be glad that data storage in the cloud grows faster than data creation in the cloud.
Many organizations believe there is latent, potentially unmined value from analyzing older data. Yet the cost to store more data holds organizations back from modifying their data retention policies that would lead to retaining data longer. This is a factor that is expected to continue to be a headwind for faster expansion of the Global StorageSphere until organizations begin to show a positive ROI on data analytics initiatives, especially with older data. (IDC)
The two concerned reports mentioned in the announcement by IDC:
- Worldwide Global DataSphere Forecast, 2021–2025: The World Keeps Creating More Data — Now, What Do We Do with It All?
- Worldwide Global StorageSphere Forecast, 2021–2025: To Save or Not to Save Data, That Is the Question
Top image: Photo by Ian Battaglia on Unsplash





