Part one of an introduction to and exploration of DataOps, including the background, definitions, evolutions, best practices, human/collaborative aspects, market data, vendors, and related data management topics. In this first article: where we come from with DataOps (and why) and where we go – with XOps.
Throughout the long history of data management, there have been numerous innovations to respond to changing business demands. Each stage in data management built on previous ones and came up with new approaches once the older ones didn’t suffice anymore.
DataOps is the discipline of connecting data creators with data consumers. (IDC)
Data being the proverbial new oil and enabler of digital transformation, speed has become essential. With the ongoing increase of data volumes, the proliferation of data sources, and demand for real-time analysis in our connected world of Industry 4.0 and rapid decision-making, speed is also a driver for new data management methods.

DataOps is one of these methods, extremely suited to leverage AI and ML. It aims to deliver insights and analytics faster to those that need them across several use cases – an overview of DataOps, what it does, and how it evolves.
DataOps – a much needed collaborative discipline inspired by the DevOps movement
Delivering the right data and information at the right time to the right stakeholders for the right purposes has become an ever more challenging task.
The challenges of information management and of data management evolved as the nature and role of information and data changed. So, a lot has changed since big data analytics and new data management solutions arrived for the world of bigger, faster, more diverse, and more (complex) data sets, a.k.a. big data.
Data management remains complex with, among others, difficulties in extracting insights and value from growing volumes of data as digitization continues, the ‘datasphere‘ continues to grow (in 2020 64.2ZB of data was created or replicated), and we sit on mountains of data that remains unused.
DataOps combines users, processes, and technologies to create a reliable, quality data pipeline that any user can translate into insights.
Delivering analytics and extracting value is hard with the reasons for failing data analytics projects revolving more around people, processes, and other organizational issues than we perhaps realize. At the same time, organizations realize that getting faster access to accurate data and speeding up the process from data to insights/actions can provide a competitive advantage in an increasingly real-time economy.
And it’s here that DataOps, which among others promises to get the right information faster for any given purpose, comes in, inspired by the DevOps movement and recognizing the need to collaborate and streamline processes using the proper methods and tools/technologies, precisely to avoid failed projects and overcome the inevitable silos.
DataOps, a contraction of ‘Data Operations,’ is a – collaborative – discipline in data management that essentially combines several elements to accelerate the process of turning data into value (good old DIKW).
Wikipedia defines DataOps as “an automated, process-oriented methodology, used by analytic and data teams, to improve the quality and reduce the cycle time of data analytics.”
Automation, processes, teams, quality, analytics, and speed: it’s clear that we’re not just looking at technology or solution. DataOps is a discipline and a method that includes people (with various backgrounds), processes, cultural change, and orchestration and collaboration tools, to mention some.
Where DataOps comes from and goes to: looking back and forward – DataOps 2021 and beyond
Born as a growing set of best practices inspired by the DevOps movement, DataOps has become an independent data analytics approach or “a new category of data access, blending, and deployment platforms that may solve data conflicts in your organization.”
That’s how Data Science Central’s Bill Vorhies Editorial Director described its evolution in 2017, a year in which some companies presented their new DataOps software platforms.
Most data analytics projects fail, mainly due to people, processes, and a lack of collaboration.
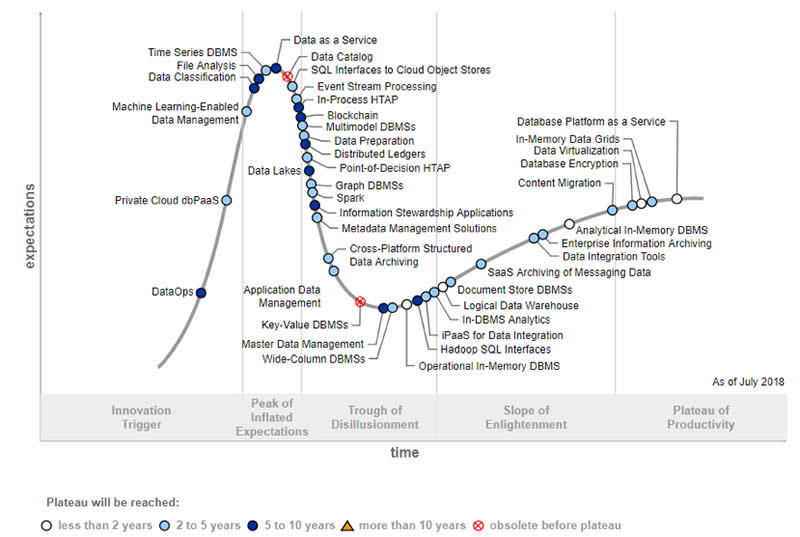
In 2018, Gartner added DataOps to its Hype Cycle for Data Management, where DataOps was one of three innovation triggers in that category. However, per research vice president Nick Heudecker, DataOps would quickly move up on the Hype Cycle.
Gartner defines DataOps in a way that will perhaps make more sense to the business people, as does IDC that stated that “DataOps looms as the missing link of data management” in a 2020 report with Seagate.
Gartner’s definition (the first sentence): “DataOps is a collaborative data management practice focused on improving the communication, integration, and automation of data flows between data managers and data consumers across an organization.” IDC’s definition: “DataOps is the discipline of connecting data creators with data consumers.”
A few words on DataOps and DevOps before looking at DataOps today and in the future. DataOps isn’t simply DevOps (software development + IT operations) applied to data.
DataOps is a solution to today’s data management dilemmas and a discipline within data management that enhances collaboration between data consumers and data creators, either of which can be humans or machines.
The DevOps movement inspired DataOps, and, as Vorhies wrote, DataOps blossomed following the formalization of DevOps…because it was recognized that the same problems solved and principles used in DevOps could be adapted to data availability. Again, a lot about people and processes indeed.
And citing Jack Vaughan in a 2017 TechTarget post: “A DataOps strategy, which is inspired by the DevOps movement, strives to speed the production of applications running on big data processing frameworks. Like DevOps, DataOps seeks to break down silos across IT operations and software development teams, encouraging LOB stakeholders to also work with data engineers, data scientists, and analysts so that the organization’s data can be used in the most flexible, effective manner possible to achieve positive business outcomes.”
Fast-forward a few years with a look at DataOps in 2020 and 2021. We start with the briefly mentioned report by IDC and Seagate, in which it is stated that DataOps looms as the missing link of data management. By the time the report was published, an increasing number of software vendors had positioned themselves in the category of DataOps tools. Just a few years earlier, only a few did, which led Vorhies to write the mentioned article, “DataOps – It’s a Secret,” back in 2017.
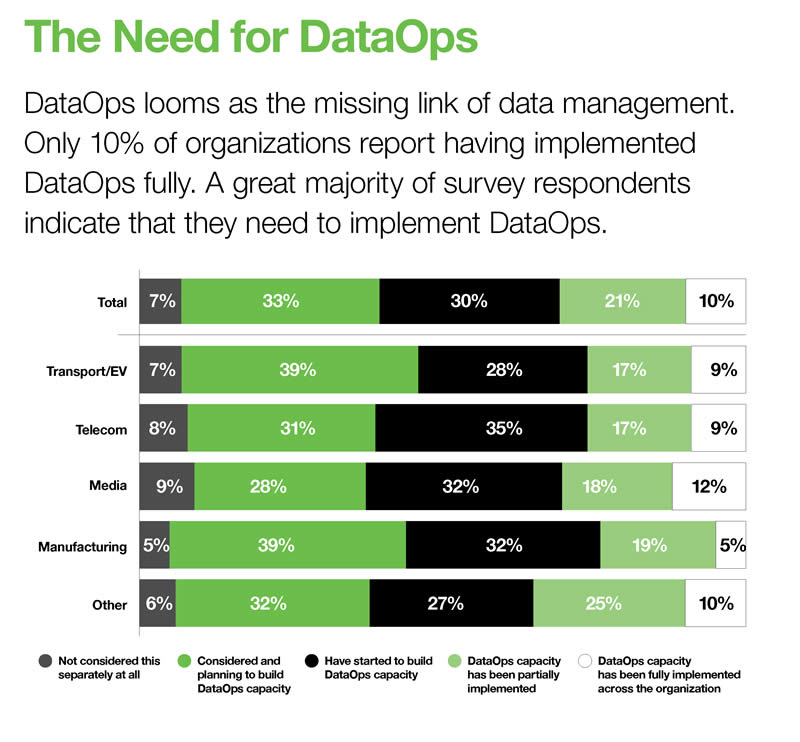
The IDC and Seagate report, entitled “Rethink Data – Put More of Your Business Data to Work – From Edge to Cloud,” found, among many other things, that DataOps is a solution to today’s data management dilemmas.
Keeping in mind that DataOps is not suited for everyone/everything, IDC found that 10 percent of surveyed organizations had fully implemented DataOps. Surprisingly, since DataOps remains relatively new, only 7 percent had not considered it separately at all.
Thirty-three percent had considered and planned to build DataOps capacity, thirty percent had started to build DataOps capacity, and another 21 percent had partially implemented it. Certainly not bad at all for a method featured in the early stage of the Innovation Trigger phase of Gartner’s Hype Cycle for Data Management.
David van der Laan, who leads a team of thirty data strategists, data scientists, data analysts & CRM analysts, sees DataOps and Agile as game-changers in data and analytics. The main reason is that all similar movements/evolutions create transparency and structurally ensure that the proper conversation occurs between data experts and ‘non-data people.’
From DataOps to XOps?
Speaking about Gartner: in its “Top 10 Data and Analytics Technology Trends for 2021“, announced in March 2021, the research firm mentioned DataOps again, yet in a somewhat changed context.
Gartner came up with XOps that includes DataOps but also MLOps, ModelOps, and PlatformOps. The rationale: they all aim to “achieve efficiencies and economies of scale using DevOps best practices, and ensure reliability, reusability and repeatability” while reducing duplication of technology and processes and enabling automation.
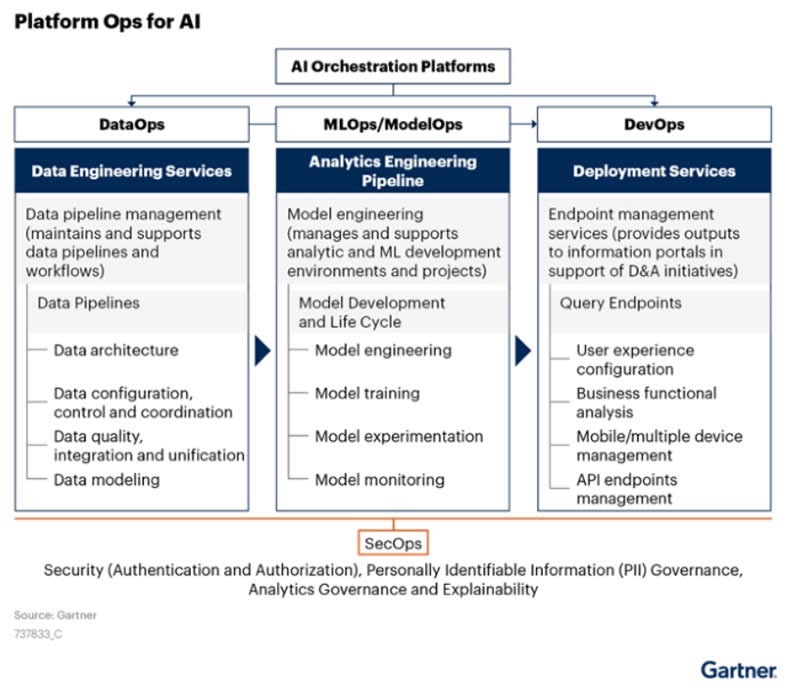
And of course, they all concern analytics and AI projects, most of which fail because operationalization is dealt with as an afterthought per Gartner.
In March 2021, the folks at VentureBeat tackled the topic as Gartner research director Soyeb Barot covered it during one of their Transform 2021 sessions (which you can all still watch).
VentureBeat emphasized that the evolution of DataOps could fix the ongoing struggle of enterprises to struggle to collaborate well around their data, which hinders their ability to adopt transformative applications like artificial intelligence.
If D&A leaders operationalize at scale using XOps, they will enable the reproducibility, traceability, integrity and integrability of analytics and AI assets. (Gartner)
Soyeb Barot stated that creating ”a common architecture pattern helps with operationalizing data science and ML pipelines and has been identified as one of the major trends for 2021″. At least as importantly, the Gartner analyst also explained the place and role of XOps. A must-read.
As for the research by IDC and Seagate: we’ll cover it more in-depth with other data management topics and plenty of interesting findings from the report, but you can/should, of course, check it out. A quote: “DataOps is particularly well suited to the iterative learning approach required by AI-driven applications.”
More on DataOps (including “how it works” and the players that offer tools) and other evolutions in data management coming soon.
In the meantime, here’s the rest of Gartner’s description/definition of DataOps (we only mentioned the first sentence):
“The goal of DataOps is to deliver value faster by creating predictable delivery and change management of data, data models and related artifacts. DataOps uses technology to automate the design, deployment, and management of data delivery with appropriate levels of governance, and it uses metadata to improve the usability and value of data in a dynamic environment.”