
Personal data is any form of data which can be used to identify an individual, natural person. In data protection and privacy law, including the General Data Protection Regulation (GDPR), it is defined beyond the popular usage in which the term personal data can de facto apply to several types of data which make it able to single out or identify a natural person.
The more data gets combined and aggregated, the more substantial the personal data becomes, the more difficult it becomes to de-identify and the higher the risks and responsibilities
In the scope of the GDPR, for instance, it includes data which can lead to the direct or indirect identification of a natural person.
As we’ll see in this article on personal data, personal data processing, personal data protection, identifiers and the data subject (the natural person which the data enable to identify) the GDPR text also broadened the definition and list of personal data in order to be more aligned with personal data types that have joined the traditional lists of personal data in this day and age of digitalization and digital transformation with, among others, data gathered via the Internet of Things (IoT); RFID tags, data from so-called sensors and actuators, anything really.

This is not just important to know for developers of applications for consumers such as smart home applications or in the sphere of consumer electronics overall where it seems obvious as these by definition are for personal usage and thus will process personal data and enable to gather all sorts of identifiers. However, also in a business context and even in the industrial space of Industry 4.0 you need to check. An example: in the manufacturing industry we see that increasingly health-related real-time data of workers are monitored via so-called wearables. It often is for security and safety of the worker and it can fit in contractual stipulations regarding the worker-employer relationship but you need to know, especially as in this example we even speak about sensitive data. So: do check if you offer one of those applications with modern-day identifiers (via a so-called data protection impact assessment).
Simply said: there is more to personal data and identifiers in the scope of the GDPR than one might think. The list of types of personal data that could lead to the identification of a natural person in this digital context further include email addresses, cookies, IP addresses and, overall, lots of online identifiers.
Personal data: more than it might seem
Sometimes an email address can be enough to identify someone. Sometimes you need a mix of online and other identifiers. Usually, the more personal data and identifiers you have and process, the stricter personal data protection rules, rights of the natural person and duties and liabilities become, with potentially higher administrative fines and penalties when there is a personal data breach, for example.
Moreover, when you have a lot of personal data and identifiers sitting a bit everywhere as tends to be the case in most circumstances the harder it de facto becomes to guarantee rights such as the right to erasure.
On our overview page of the GDPR we cover personal data, identifiers, special categories of data (‘sensitive’, genetic, health, gender, biometric, etc.) and data subjects. Here you find a deeper dive into GDPR personal data protection aspects such as pseudonymization, the data subject, personal data and the identifiers.
What are personal data (and what are they not) for the GDPR, what is personally identifiable information and when does it become sensitive personal information – or what are the identifiers that make personal data sensitive data in the GDPR?
In practice many people struggle with the ways in which they can determine when data is considered personal or not, what types of personal data are more protected (‘sensitive data’), what makes personal data processing riskier and how far the concept of personal data really stretches.
It is critical to understand these concepts in the GDPR awareness stage on your journey towards GDPR compliance. All too often mistakes are made with regards to specific types of data that are not recognized as personal data by executives while they are for the General Data Protection Regulation.
It’s one of the shortest ways to GDPR fines as not getting the essence of personal data processing and personal data types and identifiers right means the entire foundation of your GDPR plan and strategy is wrong Note: do remember that in specific cases the GDPR requires you to have a Data Protection Officer.
The application of GDPR personal data protection: processing of personal data and the data subject
Let’s start by going to Article 4 (‘Definitions’) of the GDPR as we did in our guide to GDPR and dissect each piece of the article and the related GDPR Recitals (the text that provides the reasons for the regulation and the actual articles, as you can imagine crucial to understand the scope and to interpret).
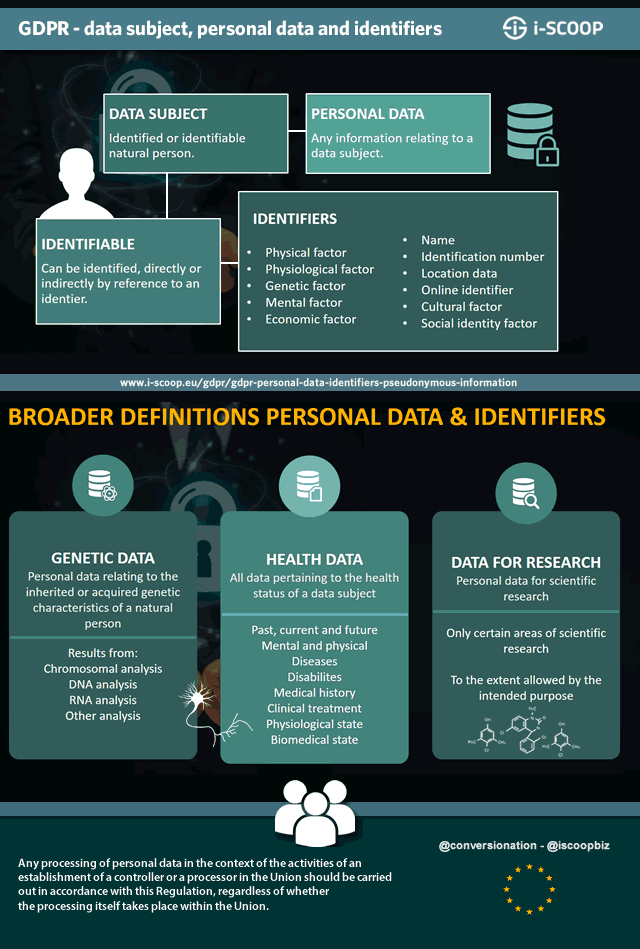
The mentioned Article 4 defines various terms used in the GDPR, almost obviously starting with the definition of personal data: ‘personal data’ means any information relating to an identified or identifiable natural person (‘data subject’); an identifiable natural person is one who can be identified, directly or indirectly, in particular by reference to an identifier such as a name, an identification number, location data, an online identifier or to one or more factors specific to the physical, physiological, genetic, mental, economic, cultural or social identity of that natural person;
The GDPR applies to the processing of personal data: personal data processing. It sets out the rules to protect personal data with the goal of protecting people’s privacy and fundamental rights.
Processing personal data describes a set of operations regarding personal data. Personal data processing is defined differently in various laws around the globe as to the types of operations included. In the GDPR, processing operations include automated and non-automated operations, with a broad definition of processing and many types of operations included.
It’s important to always keep the latter in mind when interpreting the GDPR: it’s about privacy, rights and people and, thus, about data which are personal. This is crucial as it will be key in jurisprudence and is key in how the GDPR looks at personal and sensitive data, as well as the definition of lawful processing of personal data, consent regarding personal data and so forth.
Last but not least, it’s in the combination and combined usage of personal data that the privacy risks can increase, with an additional focus on the special categories of data as we mentioned them in our overview. So, this should be your primary focus when assessing risks and vulnerabilities in your GDPR strategy: personal data breaches, risks for essential rights and protection, from the sensitivity, aggregation, purpose and usage of data perspective. And all this obviously also from the perspective of cyber risks and compliance risks, including the consequences of cybersecurity breaches.
What is personal data for the General Data Protection Regulation?
If you read Article 4(1), the definition of personal data consists of several elements which all need to be present.
If we shorten the article a bit it states that personal data is any information relating to an identified or identifiable person; the rest is a further explanation with examples as we cover them below. Let’s look at the key elements of personal data and of Article 4(1) – and what they mean in practice.
“Any information”
In the general scope of the GDPR ‘any information’ needs to be taken literally.
It can be a cookie (one of many forms of online identifiers), a name, an email address, a biometric element (facial recognition, fingerprint) used for identity verification, a person’s location, occupation, gender, a physical factor, a health-related data element, the mentioned IoT-related identifiers, indeed anything.
“Relating to”
The data relates to someone and thus can have an influence on the privacy rights of the person the information relates to.
This is the aspect of context, which is important to understand the GDPR. To make this tangible, think about a simple database or Excel sheet. Imagine it only contains a list of first names, nothing else. If it’s not fitting in a bigger context or can be traced back in relation to someone the list does not contain personal data but only first names as you would for instance use them to make a totally anonymous list of most popular first names.
When we add more context in the form of data such as job function and surname relating to the person, all the data elements, including the first name, are personal.
Natural person and GDPR data subject: identified and identifiable
A natural person is all of us: you, me and everyone else.
A business is not a natural person so the GDPR only applies to ‘real people’ within the known geographical scope of the GDPR. In the text the natural persons to whom the ‘any information relates to’ are called data subjects. That’s easy. Now we need to add the additional elements, referring to natural persons. They are data subjects if they are identified or identifiable.
Identified natural person
An identified natural person or data subject is one that is clearly known, named, identified in the true sense of being recognized, singled out, discovered and all the other meanings of identified. That’s easy too.
Identifiable.
With an identifiable natural person or data subject, things get a bit trickier in practice. There are two ways of potentially being identified. One is directly, the other is indirectly.
Personal data – identifiers in the General Data Protection Regulation
What’s important here is the element of an identifier as we mentioned in our GDPR overview.
Processing personal data describes a set of operations regarding personal data. Personal data processing is defined differently in various laws around the globe as to the types of operations included. In the GDPR, processing operations include automated and non-automated operations, with a broad definition of processing and many types of operations included.
The GDPR does not formally define what an identifier is within its scope nor provides a full list of all possible identifiers. However, the text does sum up types and broader categories of identifiers, which simply put are elements that enable identification. If you know the directive preceding the GDPR, do note that both the number of identifiers and definition of personal data have been broadened.
A first list of identifiers can also be found in our Article 4(1).
Quote: “an identifiable natural person is one who can be identified, directly or indirectly, in particular by reference to an identifier such as a name, an identification number, location data, an online identifier or to one or more factors specific to the physical, physiological, genetic, mental, economic, cultural or social identity of that natural person”.
The vast reality of identifiers: a look at online identifiers
That is indeed a large number of potential identifiers. However, if you look at each of these potential identifiers, an even vaster picture emerges.
Just take an online identifier, for instance. As mentioned this could be a cookie, with cookies already existing in many shapes and flavors for several purposes, from web analytics to advertising (note that cookies are also tackled by the lex specialis to the GDPR, the so-called ePrivacy Regulation).
Other forms of online identifiers are described in Recital 30 of the GDPR where it is clarified that natural persons may be identified with online identifiers which are provided by:
- Devices,
- Applications,
- Tools and
- Protocols, such as
- IP (Internet Protocol) addresses,
- Cookie identifiers, or others such as
- Radio Frequency Identification (RFID) tags.
All these online identifiers can leave traces which, when combined with unique identifiers and/or other information received by the servers (remember the importance of context and aggregation) can be used to create profiles of data subjects and identify them.
We’ve picked online identifiers to illustrate the vastness of possible identifiers but you can imagine the vastness of potential identifiers with regards to all the other mentioned factors, relating to pretty much about anything indeed that concerns a data subject. Depending on your industry and area of (processing) activities you need to look at the factors that could concern the privacy of data subjects within this scope.
Identifiability and identifiers in practice: the meaning of ‘all means’
Let’s make it more tangible. Your mobile telecommunications provider decides to sell information regarding location and movement patterns, based upon the movements and locations of its customers, people like you.
The sold patterns data is actually based upon aggregated data, has been disconnected from any individual location data and sits in a separate data repository which is completely detached from individual data before it gets sold. In that case the aggregated data cannot be traced back to individuals.
If, however there is a way that the location data can be connected to an individual, not by the buyer of the patterns information but by the provider, it becomes trickier as the customer could be identifiable by means of the provider and the provider’s other data about its users/customers.
Now, imagine that instead of selling information on patterns, the provider would sell real-time data on where all its customers are at any given time, without enabling the buyer to know to whom this location data is related. In this case, despite the fact that the buyer of the real-time data only sees the location, the identifiability, by means of the provider, gets clearer and the location data would likely be considered as personal data.
In Recital 26 the GDPR states “To determine whether a natural person is identifiable, account should be taken of all the means reasonably likely to be used, such as singling out, either by the controller or by another person to identify the natural person directly or indirectly.” “All means reasonably likely by the controller or another person” in the second part of our example would likely include the provider and needs to be interpreted broadly.
The GDPR, anonymous information and pseudonymization
Although our example is not fiction, certainly where it concerns data patterns (the part where links with individuals are removed), there are two additional elements we need to add here.
The first is anonymous information (which doesn’t fall under the GDPR and is used in the cases of selling location data patterns which we know). The second is pseudonymization, whereby data where pseudonymization is applied does fall under the GDPR (it is mentioned in GDPR Recital 28).
Pseudonymisation is one of the “appropriate technical and organisational measures to ensure a level of security appropriate to the risk
Before explaining them do keep in mind it’s important to really look at examples of how you sell or leverage data and informaton with third parties.
We used the example of a telecommunications provider but you can also think about medical research or trials whereby three or more parties are involved: the data subject, a doctor, hospital or any other organization asking the data subject to participate, the labs conducting the needed test or tests and, potentially, more stakeholders. Even if the lab might only have your individual test results they are identifiable as other instances and stakeholders can trace them back to you.
It’s in real-life examples that anonymous information and pseudonymization becomes even more important.
The GDPR and anonymous information
Recital 26 of the GDPR says: “the principles of data protection should not apply to anonymous information, namely information which does not relate to an identified or identifiable natural person or to personal data rendered anonymous in such a manner that the data subject is not or no longer identifiable. This Regulation does not therefore concern the processing of such anonymous information, including for statistical or research purposes”.
Going back to our example of the mobile operator: in reality the sold patterns are in fact statistics and entirely rendered anonymous. The data subject can’t be identified.
In the example of medical research or trials (‘research purposes’) information would be anonymous – and thus not subject to GDPR – if all test lab results are completely detached from the individual patient, all possibly links with the individual are destroyed/removed/deleted and thus the results are also never communicated to patient/volunteer, hospital, doctor and any stakeholder whatsoever. So, again, making identification impossible.
In any other case it falls under the GDPR. Simply said: if the lab does not have any link between the test results and you but the hospital, specialist or organization that asked you to participate has (and possibly shares the results with you), the test result would be personal data as it can be traced back to you by means of the specific instance that can link the result and your other data (remember how context makes personal data a privacy risk; in general the more data the higher the privacy risk), such as the hospital.
The GDPR and pseudonymization: the essential elements
Quoting from Recital 26: “Personal data which have undergone pseudonymisation, which could be attributed to a natural person by the use of additional information should be considered to be information on an identifiable natural person”.
In other words: pseudonymous data are protected by the GDPR. Whereas with anonymous information there is no more potential identification of the data subject, with pseudonymization there is.
As, opposed to anonymous information, pseudonymization of data, falls under the GDPR it comes back at in several recitals and articles of the GDPR, among others with regards to the responsibilities of the data controller, personal data breaches, security of processing and so forth.
There are two key aspects to remember here:
1. Pseudonymization is recommended where feasible in the GDPR.
Along with encryption of personal data, pseudonymization is explicitly mentioned as one of the “appropriate technical and organisational measures to ensure a level of security appropriate to the risk”. In other words; it is recommended, where appropriate and feasible as Article 32(1,a) of the GDPR (the text we just mentioned) states.
As you can read in our article on GDPR readiness, research found that 54% of multinationals in the US plan to use such methods of de-identification to reduce GDPR risk exposure.
2. Pseudonymization falls under the GDPR because of the potential of “unauthorised reversal of pseudonymisation”.
Again, we need to emphasize the key role of the data subject’s perspective. Pseudonymization is the result of uncoupling certain aspects of data from a data subject (often as part of security precautions and analytics) whereby the data fields which are the most identifying and/or sensitive in a data record are replaced by pseudonyms. Yet, it can be reversed or in other words: the personal data that is pseudonymized can be retrieved.
The GDPR defines pseudonymisation as follows in Article 4(5):
‘pseudonymisation’ means the processing of personal data in such a manner that the personal data can no longer be attributed to a specific data subject without the use of additional information, provided that such additional information is kept separately and is subject to technical and organisational measures to ensure that the personal data are not attributed to an identified or identifiable natural person;

In conclusion – GDPR and personal data protection
To conclude, a small recap. The GDPR is designed to protect personal data in order to protect privacy and individual’s rights (which are not absolute).
This does not include anonymous data but all other information whereby a data subject is identified or identifiable, directly or indirectly. This also includes pseudonymized personal data.
Context is important. The more data gets combined and aggregated, the more substantial the personal data becomes and the more difficult it becomes to de-identify and the higher the risks and responsibilities – and the potential GDPR fines and penalties.
Next in regulations and compliance: EU DORA Digital Operational Resilience Act
Top image: Shutterstock – Copyright: Alfa Photo – All other images are the property of their respective mentioned owners. Although the content of this article is thoroughly checked we are not liable for potential mistakes and advice you to seek assistance in preparing for GDPR.





