
The General Data Protection Regulation (GDPR) explicitly recommends pseudonymization of personal data as one of several ways to reduce risks from the perspective of the data subject, as a way for data controllers to enhance privacy and, among others, making it easier for controllers to process personal data beyond the original personal data collection purposes or to process personal data for scientific and other purposes (as we’ll see with an example).
Pseudonymization is a technique that is used to reduce the chance that personal data records and identifiers lead to the identification of the natural person (data subject) whom they belong too. Identifiers make identification of a data subject possible.
If you replace the most identifying fields in a data record by one or more pseudonyms, which are fictional identifiers (in the form of codes, randomly generated token, data strings that look real but aren’t, values and so on; there are many techniques) you decrease the risk of identification, reduce potential concerns regarding the data processing operation and are that little bit closer to a higher degree of protecting the data subject rights and risks in the broadest possible sense and within the scope of purpose limitation. Why? Because you only use real data where real data are needed (in practice there are several databases of course and data needs to be classified and analyzed for sensitive data which are not needed).

Pseudonymization and reversal of pseudonymization (reidentification)
With the GDPR it’s the first time that pseudonymization is introduced in the data protection and privacy laws of the EU. Pseudonymization, while recommended, isn’t the easiest nor ideal solution for all circumstances though and, as such or even in combination with the necessary technologies isn’t your ticket out of the GDPR.
With pseudonymized data, depending on the used technique, the detachment of certain fields/identifiers from the personal data record can be reversed. Do not confound pseudonymization with encryption, a data protection technique which is also recommended by the GDPR but is something entirely different. There is also a difference between pseudonymization and anonymization. Quoting from Article 29 Working Party Opinion 05/2014 on Anonymisation Techniques (1): “Pseudonymised data cannot be equated to anonymised information as they continue to allow an individual data subject to be singled out and linkable across different data sets”.
The GDPR protects identified and identifiable natural persons, a.k.a. the data subjects. Identifiers can be spread across several data records and sit in data records where (depending on what one or more parties involved in the data processing operation can do) several fields can be pseudonymized. Pseudonymous data falls under the scope of the GDPR.
So, as we wrote in the previously mentioned article, pseudonymization enables to uncouple specific data aspects from a data subject whereby the most identifying and/or sensitive data fields in the record are replace by pseudonyms. Yet, as said, pseudonymization can be reversed. This is of course not a problem as such. The example below shows why that reversal is necessary. However, only people who have the authorization to reverse it can do so. When the reversal of pseudonymization is not authorized there is a problem: unauthorized reversal is a personal data breach (if it means a risk for the data subject).
It must be said that de facto the reidentification of data which have undergone pseudonymization (and even anonymization) isn’t that obvious. Often a distinction is made between direct and indirect identifiers and indirect identifiers can lead to identification when additional data are leveraged.
Moreover, there are several techniques of pseudonymization (and reversal of it) so to minimize the risk of unauthorized reversal, data controllers must use several technical and organizational measures to make sure that the pseudonymous information is really detached from the key enabling (re)identification.
Such techniques and organizational measures include adherence to the privacy by design principles (of which pseudonymization is, literally, part in the GDPR) and techniques such as encryption (as said, also recommended by the GDPR), tokenization and hashing.
However, back to the essence as we don’t want to get too technical and added some additional information on all the mentioned terms below.
How pseudonymization can be used under the GDPR
Let’s give an example of situations where pseudonymization gets used (in a somewhat simplified way).
In several data processing operations many parties are involved. Take scientific research (which we mentioned earlier as an example) in healthcare, whereby data subjects are requested by their physician if they want to join the research program.
With medical research and personal medical data we are in the context of special categories of personal data which are even more protected. When your doctor asks you to join such a program you typically have other parties involved: for instance, the hospital and the research lab (and pharmaceutical companies, depending on the scope of the research).
The research lab doesn’t need to know who you are, it just needs to conduct the research tests based upon specific personal data (or fields in data records). The hospital normally doesn’t need all data either (although it can have loads of data of course, for instance in the scope of an electronic health records program, which is another ballgame). Yet, strictly speaking the hospital doesn’t need to know where you live, for instance, if in the scope of this research program it is a scientifically involved party or conducts some basic tests which the test lab will need (also the physician can do some of those) and not supposed to contact or know you.
These are types of circumstances where peudonymization comes in. The research lab can only see what it needs to in order to conduct the tests, full stop. The hospital theoretically only needs to see what it needs to see, for instance the name and address of your doctor in order to know where to send the results and maybe the results of some preliminary tests it conducts in order to provide the test lab the ‘material’ it needs. The doctor/physician sees everything. So, just as pseudonymization goes in one direction, the reversal of it (de-identification) goes in the opposite direction and that is made possible with strict agreements, rules, mentioned additional measures (technical and organizational) and of course the possibly to retrieve the data from those pseudonymized fields, using the (de-)identification key or whatever is used in one of the peudonymization solutions.
Pseudonymization is recommended but shouldn’t be used as a way to separate identifiers from data subjects regarding personally identifiable information in order to circumvent other obligations. Pseudonomyzed information falls under the scope of the GDPR AND pseudonymization is meant to decrease the data subject’s risks, not as some trick to bypass other rules.
IDC also makes the case for often overlooked tools (and processes) across the domains of security and information governance, including tools to pseudonymize data, as IDC’s Philip Carnelley wrote in a blog in July 2017, showing the place of it all in the GDPR technology framework of the research firm.
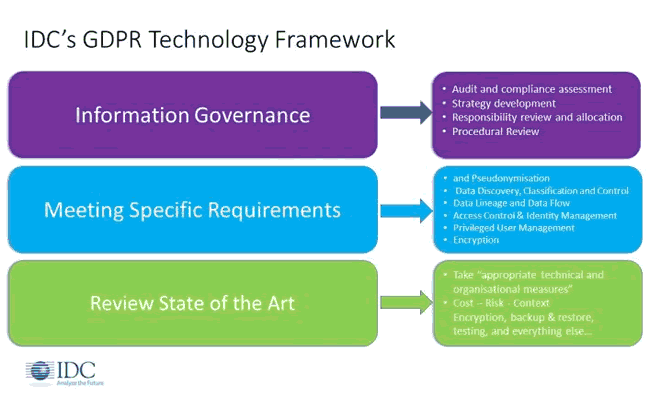
What the GDPR says about pseudonymization – and you should know
There is far more to be said about pseudonymization, whether it concerns techniques, types of applications, incentives provided by the GDPR to use pseudonymization, circumstances in which not to use it and so on.
Let’s take a look at what the GDPR says about pseudonymization with additional comments to put it all in perspective.
GDPR Recitals and pseudonymization
GDPR Recital 26 covers the essential application of the GDPR regarding both personal data which have undergone pseudonymization and personal data which are rendered anonymous.
The data protection principles of the GDPR apply to an identified and identifiable natural person whereby personal data which have undergone pseudonymization are considered information on an identifiable natural person (and thus are protected by the GDPR) if the personal data which have undergone pseudonymization could be attributed to a data subject by the use of additional information.
To gauge whether the latter is the case and the data subject can be identified (is identifiable) in the context of pseudonymization, all the means reasonably likely to be used must be considered, including singling out, by the controller or by another person to identify the natural person directly or indirectly.
The principles of data protection do not apply to anonymous information, which is information that doesn’t relate to an identified or identifiable natural person or to personal data rendered anonymous in a way that it doesn’t make the data subject identifiable.
GDPR Recital 28 recommends pseudonymization as a way to reduce the risks for data subjects AND to help data controllers and data processors meet data protection duties, in other words to be compliant. However, the fact the the GDPR eplicitly introduces pseudonymization does not mean that it precludes other security and data protection measures.
GDPR Recital 29 offers incentives to data controllers to use pseudonymization and GDPR Recital 75 mentions unauthorized reversal of pseudonymization among the risks and freedoms of natural persons.
GDPR Recital 78 in a way is also an incentive in the sense that it recognizes “pseudonymization of personal data as soon as possible” as one of many ways that help in demonstrating GDPR compliance (which is a duty), just as adhering to codes of conduct and data protection impact assessments are some ways to demonstrate compliance.
GDPR Recital 85 mentions an unauthorized reversal of pseudonymization as one of the personal data breaches that can trigger the personal data breach notification duty of the controller towards the supervisory authority and, finally, GDPR Recital 156, mentions pseudonymization of data as one of the safeguards which, if they exist, can be used by controllers to assess the feasibility of further processing of personal data for archiving purposes in the public interest, scientific or historical research purposes or statistical purposes by processing data which do not permit or no longer permit the identification of data subjects.

GDPR Articles and pseudonymization
For all the Articles in the GDPR text regarding pseudonymization please do check out our searchable list of GDPR Articles.
They start with GDPR Article 4, defining “pseudonymisation as the processing of personal data in such a manner that the personal data can no longer be attributed to a specific data subject without the use of additional information, provided that such additional information is kept separately and is subject to technical and organisational measures to ensure that the personal data are not attributed to an identified or identifiable natural person”.
GDPR Article 25 about data protection by design and by default clearly makes the case for pseudonymisation as one of those measures designed to implement data-protection principles whereas GDPR Article 32 mentions both pseudonymisation and encryption in the scope of security of processing.
More on pseudonymization, anonymization and de-identification
Pseudonymization isn’t the easiest of topics in practice nor is a thorough understanding of pseudonymization, anonymization, de-identification and so forth. Pseudonomyzation also doesn’t only offer benefits.
Quoting from a PwC November 2017 newsletter article from Data Protection Officer Cédric Nédélec on the topic: “Numerous pseudonymisation techniques are available. They come in a variety of price ranges and security guarantees and they can also slow down processes. Pseudonymisation must therefore be considered in terms of the sensitivity of the data being processed and with regard to the assessment of its impact on data subjects during processing. One should keep in mind that data subjects may be reidentified, directly or indirectly, on the basis of partial information or a combination thereof”.
In June 2017 article on the GDPR’s impact on security and data protection programs, Forcepoint’s Larry Austin mentions research (from Osterman Research) showing that from a data protection technology spending perspective in the scope of GDPR compliance, data loss prevention, network protection and endpoint protection precede encryption, tokenization and pseudonymization for data at rest (and endpoint security ranking before encryption, tokenization and pseudonymization for data in use).
In a July 2017 blog, Brian Cave, looks deeper at the topics of de-identification, pseudonymization and anonymization with the mentioned input from the Article 29 Working Party which is also mentioned by Cédric Nédélec (so, when the GDPR didn’t exist yet but there was a Directive) in the scope of Anonymization Techniques that definitely is worth a look.
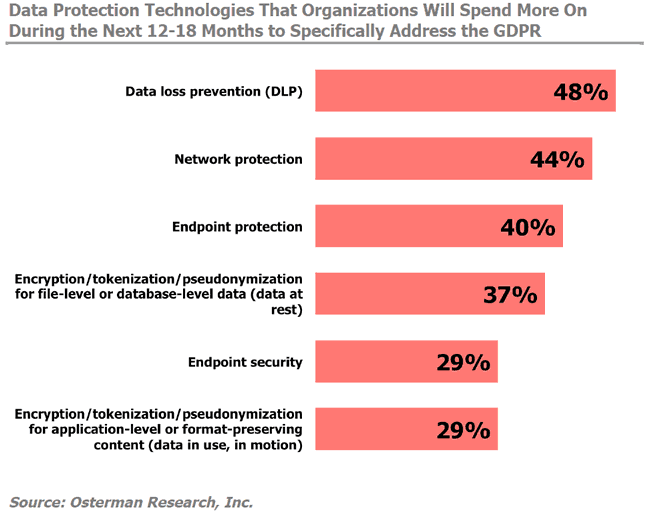
Finally, do note that just having encryption and pseudonymization in place doesn’t mean that GDPR doesn’t apply to you, which seems to be one of many GDPR myths.
(1) Opinion 05/2014 on Anonymisation Techniques, Article 29 Data Protecion Working Party (PDF opens)
Next in regulations and compliance: EU DORA Digital Operational Resilience Act
Top image: Shutterstock – Copyright: igorstevanovic – All other images are the property of their respective mentioned owners. Although the content of this article is thoroughly checked we are not liable for potential mistakes and advice you to seek assistance in preparing for EU GDPR compliance.





