
As data lakes continue to grow and the role of analytics has become critical, businesses are revisiting their big data processing strategies.
The Big Data Trends and Challenges Report offers insight into some of the evolutions regarding different big data approaches. We look at the findings regarding big data processing and the shift to cloud and machine learning initiatives in this data age.
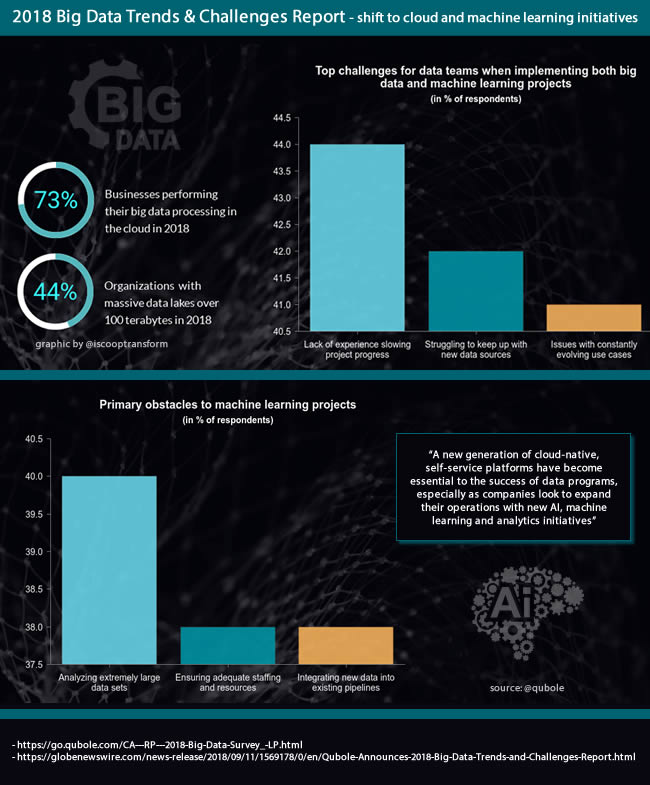
73 percent of businesses are now performing their big data processing in the cloud (Qubole)
The big data processing shift to cloud platforms
The ongoing shift of big data processing to the cloud is one of the key takeaways of the 2018 Big Data Trends and Challenges Report. It shows that the percentage of businesses performing their big data processing in the cloud went up from 58 percent in 2017 to 73 percent in 2018.

As Ashish Thusoo, co-founder and CEO of ‘data activation’ Qubole that commissioned the 2018 Big Data Trends and Challenges Report (conducted by Dimensional Research) puts it: “the size, diversity, and applications of big data are accelerating at a near-exponential rate…businesses are quickly discovering that traditional data management systems and strategies are no longer capable of supporting their demands…a new generation of cloud-native, self-service platforms have become essential to the success of data programs, especially as companies look to expand their operations with new artificial intelligence, machine learning and analytics initiatives.”
The shift towards cloud is necessitated in part due to the ever-growing volume and diversity of data that companies are dealing with, as 44 percent of organizations now report working with massive data lakes over 100 terabytes in size (Qubole)
Among the reasons of this rapid shift of big data processing to the cloud:
- The value of on-premises big data environments is below expectations which, in turn, has several causes. Think infrastructure complexity, decisions related to facilities, a growing demand for power and performance, the need for skilled people, those digital transformation initiatives and of course costs. “As a result,” the 2018 Big Data Trends and Challenges Report states “companies are rapidly shifting to the cloud for applications centered around machine learning and analytics”. It’s also here that DataOps comes in.
- A second driver of the shift to cloud is the ever-growing volume and diversity of data that companies are dealing with, whereby organizations focus on getting more value from their data, as they seek more advanced use cases and diversify their workloads. An illustration of the growing volume: according to the survey 44% of responding companies now work with data lakes over 100 terabytes in size (compared to 36% in 2017).
- Finally, and directly related with the on-premises challenge (although on-premises isn’t gone yet) there are the benefits of cloud (scalability, ease of implementation and management, the availability of the power needed for big data processing and, as the report reminds, the fact that cost-effective self-service platforms and elastic computing are readily available).
The shift to the cloud obviously isn’t new. Yet, it accelerates and not without consequences since the movement to the cloud and optimization of data platforms for analytics go hand in hand and de facto are big transitions for organizations.
After the report was announced CEO Ashish Thusoo wrote a blog post at the occasion of the merger of Cloudera and Hortonworks, emphasizing how on-premises Hadoop vendors have not fulfilled their claims of delivering value and that on-premises infrastructures cannot offer the agility and scalability required for complex big data and machine learning projects.
The expansion of machine learning initiatives, enabled by the shift of big data processing to the cloud
A second topic covered in the 2018 Big Data Trends and Challenges Report concerns the expected expansion of machine learning programs, facilitated by this shift to the cloud.
Machine learning is being used in diverse initiatives that include crucial security, maintenance, customer care, and lead generation applications. But like most data-intensive solutions, machine learning presents a variety of implementation challenges.
Machine learning programs are expected to expand across a wide range of use cases in the next year, Qubole states.
Looking at the main priorities for these machine learning programs, the report found that:
- Improving data security and threat protection is the top priority in a world where cybersecurity can’t be an afterthought.
- Optimizing customer experience is a priority for 49 percent of respondents.
- Predictive maintenance, one of the main Industrial IoT and Industry 4.0 use cases, is a priority for 43 percent of respondents.
When looking at the types of big data processing the 2018 Big Data Trends and Challenges Report found that machine learning is done by 40 percent of organizations in the survey. That’s the same percentage as streaming data.

App data integration and ad hoc analytics are still the main types of big data processing. Yet, with an expansion of machine learning programs in the next year, expect that percentage to grow. How much precisely will, among others depend on the machine learning obstacles respondents encounter, on top of big data challenges.
Among these machine learning project challenges: analyzing extremely large data sets (40% of respondents), ensuring adequate staffing and resources (38%) and integrating new data into existing pipelines (same).
More about those and other findings from the 2018 Big Data Trends and Challenges Report on topics such as the usage of big data frameworks, talent shortages and so forth can be downloaded here.
You can also read this blog post that offers more insights and, among others highlights that “organizations are storing and processing increasingly vast amounts of data in the cloud for sophisticated use cases such as machine learning, ad hoc analysis, application data integration, and data streaming”.

The 2018 Big Data Trends and Challenges Report is based upon a survey of 401 IT and data professionals with big data responsibilities. Qubole is a provider of a cloud-native data platform for analytics and machine learning that promises to rapidly activate large volumes of data while lowering costs under the motto “Turning Data Lakes into Profit Centers”.
All images belong to their respective mentioned owners.





