GLM-5-Turbo, an LLM optimized for OpenClaw
GLM-5-Turbo is interesting for one simple reason. It is not being presented as just another general purpose chatbot model. Z.ai positions it as a model built specifically for OpenClaw style agent workflows, and OpenRouter listed it as released on March 15, 2026 with a roughly 200K context window. In the official model documentation, Z.ai says GLM-5-Turbo was optimized from training time for tool invocation, instruction following, scheduled and persistent tasks, and long chain execution. That makes it less about polished one shot answers and more about reliable execution over many steps.
To understand why that matters, you first need to understand OpenClaw. OpenClaw is a self hosted gateway for AI agents that connects chat channels such as WhatsApp, Telegram, Discord, and iMessage to an always available assistant running on your own machine or server. It is built around sessions, memory, tools, and multi agent routing. In other words, OpenClaw is not only about generating text. It is about turning a message into a sequence of actions that can touch files, call tools, work across channels, and persist over time.
What GLM-5-Turbo is
At the model level, GLM-5-Turbo is a text in and text out foundation model in the GLM family. Z.ai lists a 200K context window, up to 128K output tokens, multiple thinking modes, streaming output, function calling, context caching, structured output, and MCP support. Those are not random feature bullets. Together, they describe a model designed to sit inside a larger system where it has to reason over large working context, call external functions correctly, and return outputs that software can actually use.
That feature mix is what makes GLM-5-Turbo feel more like infrastructure than a pure chat interface. If you are building an OpenClaw agent, you are usually not asking for a short answer in isolation. You are asking the model to inspect context, decide whether it needs a skill or tool, execute part of the task, read the result, and continue without losing the thread. Z.ai is explicitly framing GLM-5-Turbo around that kind of agent behavior, and it even introduced a dedicated benchmark called ZClawBench around real OpenClaw task categories such as environment setup, software development, information retrieval, data analysis, and content creation.
Why OpenClaw needs a specialized model
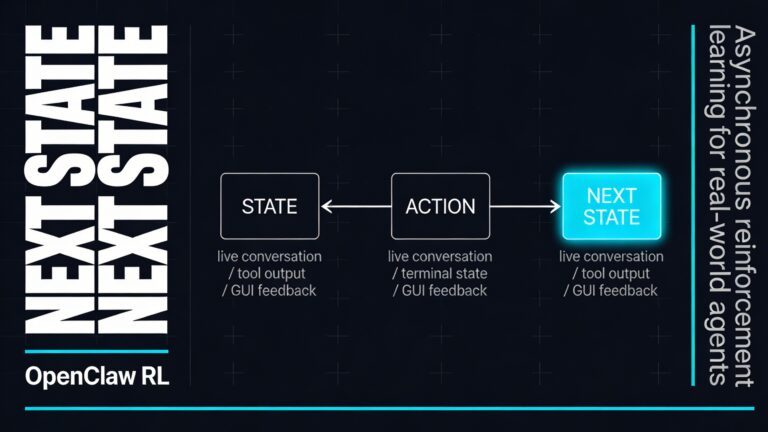
OpenClaw itself gives you a clue. Its agent loop is not a single prompt and reply. The platform describes the loop as intake, context assembly, model inference, tool execution, streaming replies, and persistence, with runs serialized per session to avoid races and keep session history consistent. Its system prompt can inject tool descriptions, skill references, workspace details, documentation hints, and session state. Skills are modular instruction bundles stored as folders with a SKILL.md file, which means the model has to decide when to load and use them rather than just answer from fixed internal knowledge.
This is where a generic model often starts to wobble. Multi step agent work is harder than a normal chat because the model has to stay aligned across many turns, preserve intent, pick the right tool at the right moment, and recover cleanly when the task stretches over time. Z.ai says GLM-5-Turbo was trained around those exact requirements. The official page highlights better tool calling stability, stronger decomposition of complex instructions, better handling of scheduled and persistent tasks, and faster, more stable execution in high throughput long chain workflows. That is exactly the layer where OpenClaw succeeds or fails in daily use.
How it works in practice
If you use GLM-5-Turbo inside OpenClaw, the workflow is usually straightforward from the outside and quite structured underneath. You send a message in your preferred channel. OpenClaw resolves the session, loads the right workspace and agent state, assembles the system prompt, exposes tools and eligible skills, and then passes that structured context to the model. The model decides what to do next, whether that means answering directly, calling a tool, or continuing a longer execution path. OpenClaw then executes the tool, streams events back, persists the session, and sends the final result to you.
On the Z.ai side, function calling works by giving the model a list of callable tools with names, descriptions, and parameters. The model returns a tool call with structured arguments, the application executes that function, then the result is sent back to the model so it can continue and produce a final answer. Z.ai also documents tool streaming output, which means reasoning text, normal response text, and tool call information can be streamed in real time instead of being buffered until the end. In OpenClaw, the Z.AI provider enables tool call streaming by default, which fits the way agent runs are already streamed through the platform.
Another important piece is memory efficiency. Context caching on Z.ai automatically recognizes repeated prompt content, such as stable system instructions or repeated conversation history, and reuses previous computation. Z.ai says this reduces both token consumption and latency. That matters a lot in agent systems because the same instructions, skill descriptions, and long running context often appear again and again. Instead of paying the full cost every time, repeated context can be handled more efficiently.
The main benefits of GLM-5-Turbo
More reliable tool use
The clearest advantage is tool reliability. Z.ai is directly emphasizing more precise and stable tool invocation for OpenClaw tasks. In an agent workflow, that is not a small upgrade. It is the difference between a model that can actually move a task forward and one that keeps getting stuck in partial plans or malformed calls. If your workflow depends on browser actions, file operations, scheduling, or external APIs, better tool behavior is usually more valuable than slightly nicer prose.
Better handling of complex instructions
GLM-5-Turbo is also aimed at jobs that arrive as messy real world requests rather than neat prompts. The documentation says the model is stronger at decomposing complex, layered, long chain instructions. That is a major benefit in OpenClaw because users often message agents the way they would message a coworker. They mix goals, constraints, follow ups, and references to earlier context. A model that can break that into a workable plan is easier to trust over long sessions.
Stronger support for long running work
Many chat models are fine for quick turns and much weaker once the task spans time. GLM-5-Turbo is explicitly optimized for scheduled and persistent tasks, plus long chain execution. Combined with OpenClaw’s session based runtime and persistence layer, that makes the model a better fit for workflows such as monitoring, staged research, recurring admin work, and multi phase build or debugging tasks. You are not only asking the model to answer. You are asking it to stay coherent while work unfolds.
Large working memory and production friendly outputs
A roughly 200K context window and up to 128K output tokens give you room for large instructions, big conversation histories, logs, documents, and structured intermediate results. Add structured output and MCP support, and GLM-5-Turbo becomes easier to integrate into real systems. You can use it for JSON shaped outputs, external tool ecosystems, and workflows where downstream software expects predictable structure rather than free form text.
Faster feedback during execution
Streaming matters more than it first appears. In an agent workflow, waiting for silence is frustrating because you do not know whether the model is thinking, calling a tool, or failing. Z.ai’s streaming support lets you surface reasoning content, partial answers, and tool call details as the run happens. OpenClaw is already built around streamed assistant and tool events, so GLM-5-Turbo fits naturally into that interaction model. The result is a system that feels more transparent and less like a black box.
A cost profile that makes repeated use easier
According to Z.ai’s pricing page, GLM-5-Turbo is listed at $1.2 per million input tokens, $0.24 per million cached input tokens, and $4 per million output tokens. That does not make it the cheapest model in the catalog, but it does show a pricing structure designed for repeated production use, especially when caching can reduce the cost of stable prompts and repeated history. For agent systems that stay alive across many sessions, that matters more than headline benchmark talk.
Where GLM-5-Turbo fits best
If you are wondering where this model makes the most sense, the answer is usually wherever you care more about execution than small talk. Good examples include coding assistants inside OpenClaw, multi step research workflows, internal operations agents, content systems that combine retrieval and structured generation, and assistants that rely on reusable skills. OpenClaw’s own architecture is built around channels, sessions, skills, tools, and isolated agents, so a model tuned for that environment has a more obvious home than a model optimized mainly for consumer chat.
- Software development and debugging across long sessions
- Research workflows that mix retrieval, summarization, and follow up actions
- Operations work that depends on consistent tool use and clear state
- Skill driven assistants that need modular capabilities instead of one giant prompt
- Persistent personal or team agents running through OpenClaw channels
What you should still watch
A model being better at agency also means you should take boundaries seriously. OpenClaw’s security documentation is very clear that tool access, browser access, filesystem access, and session logs all create real exposure. The project recommends tight channel controls, restrictive tool policies, and sandboxing for sensitive execution. It can run tools inside Docker containers to reduce blast radius, and the default sandbox workspace can be kept separate from your main agent workspace. If you plan to give GLM-5-Turbo real tools, the quality of your security setup is part of the product, not an afterthought.
That does not weaken the case for GLM-5-Turbo. It actually clarifies it. The value of this model is not that it makes OpenClaw magically safe or simple. The value is that it is designed for the exact kind of tool rich, long horizon workflows where OpenClaw already operates. If you combine that specialization with sane permissions, sandboxing, and a clear agent scope, you get a much stronger foundation for real agent work than you do with a generic model dropped into the stack without adaptation.
Why this model matters
The bigger takeaway is that GLM-5-Turbo represents a useful shift in how LLMs are being packaged for practical systems. Instead of promising to do everything equally well, it focuses on one demanding category of work and optimizes for it. If you use OpenClaw as a serious agent runtime, that focus is exactly the point. You want a model that can follow complex instructions, call tools cleanly, stay stable over long chains, and keep working when the job stops looking like a chat. That is the real advantage of GLM-5-Turbo.