
Enterprise information management and GDPR expert Rick Gruijters of Belgium-based IRIS Professional Solutions takes us on a strategic, information governance and holistic journey towards GDPR compliance.
What does the General Data Protection Regulation (GDPR) require you to do on an EIM (Enterprise Information Management) GDPR strategy level? What do you need to take into account from a records management perspective? Capture and retention schemes? Contect classification? Ensuring privacy by design with best-in-class information management practices? An illustrated overview with a staged information management GDPR strategy.
In our overview of the GDPR we zoomed in on several aspects to consider in your GDPR compliance journey, such as the need for a GDPR strategy, the importance of GDPR awareness, the role of information management and security, the essential data subject rights, including ‘new’ rights such as the right to data portability and right to erasure, the broader scope of personal data and identifiers under the GDPR, the essential data processing principles, the legal grounds for lawfully processing personal data and far more.

Yet, how do you achieve it all in practice from the enterprise information view? It all starts with strategy and requires a staged approach with a plan as the best way to avoid administrative fines and, more importantly, personal data breaches. In this article/interview we take a deep dive into the mentioned ECM, capture, retention and records management aspect with EIM and GDPR expert Rick Gruijters. We look at how in practice both data controllers and data processors can move from an awareness stage, assessment and methodology stage to an implementation stage, addressing the information management challenges and solutions to conduct risk assessments, tackle privacy by design, deal with the right to erasure and the need to know where information sits, using records management, automatic classification, retention schemes and more.

Our guide, Rick Gruyters, heads the enterprise information management division at IRIS Professional Solutions (IRIS is a Belgium-based, internationally active Canon company). The article (an interview) is spiced with handy visual overviews from one of many presentations Rick and his colleague Bart Donné CSO have given on the topic.
As mentioned previously many organizations are still in or just beyond the awareness stage of the GDPR as ample research shows and Rick Gruijters confirms. If you are only in the GDPR awareness stage when you read this, do realize that the so-called GDPR deadline of May 25th, 2018 is not the end. After reading this interview you’ll understand why, what you need to do and why in reality you can’t really be fully GDPR compliant and must proceed with a GDPR strategy and plan as explained below.
Why GDPR compliance is a business challenge and a GDPR strategy is essential
Rick, you say that the GDPR is a business challenge. Strategy, however, often proves to be a pain point; overall and certainly in a GDPR project. Let’s start with that business challenge and strategy aspect before zooming in on information management.
Rick Gruijters: There are several reasons why the GDPR is first and foremost a strategic business challenge. One of them is that, despite the fact we’re an information management and IT company, we always start from business challenges. And that corresponds with the market reality: today most challenges de facto come from the business instead of from IT. A project needs a solid business case and as a company you try to respond to it with partners and solutions.
On top of this shift of the role of business in IT, the GDPR really is a business challenge as such, even if it is an imposed one with some serious potential consequences if you don’t act upon it. You can also see it as a positive business challenge and have your business stand out as one that is really putting its customers – and their data – first. Moreover, as we discussed earlier, it’s also an opportunity to streamline your information processes with the known benefits of doing so in this day and age.
A strategic GDPR plan prioritizes the highest risks and delivers the highest impact of your GDPR projects
The strategic necessity is clear, yet underestimated. If you look at the GDPR as a business challenge, then what is the essence that shaped your strategic approach?
Rick Gruijters: The GDPR essentially requires that organizations can effectively demonstrate that they did what they could to process personal data in a more careful way. From that business challenge perspective we started looking at how information management can facilitate this and, that, in turn led to a strategic approach to GDPR in three stages.

Strategy is indeed not emphasized enough and that is a mistake.
You simply need to know what you are going to do in order to be ready to show that you did all the possible when authorities ask you to. If you don’t have an overall strategy to begin with, you can’t demonstrably prove that you tried to do what you had to and have a plan of action going forward. Tackling the GDPR business challenge is not a matter of tweaking, changing or solving some – isolated – things here and there.
However, organizations are already busy and time is money. It’s not as if they have a department that has the bandwidth to suddenly add the GDPR business challenge to their tasks. Yet, with a very decent strategic plan that looks at the aspects with the highest risks first (editor’s note: in the GDPR it is stipulated that you need to look at risk from the data subject’s privacy perspective), the impact of your GDPR actions in turn will be the highest possible.
GDPR awareness as a strategic quick win that shows you act
The three steps or stages you came up with contain many underlying actions, processes and domains to focus on. Can you just summarize each one and explain its importance?
Rick Gruijters: The first one is awareness; becoming conscious and aware of (the impact of) the GDPR. Most organizations are indeed still in this stage. Making your organization aware about the GDPR encompasses various aspects and isn’t just for management.
What management needs to do, however, is make sure that all employees are aware of the GDPR and what it means for their work: explaining what the GDPR is, what is coming their way as a consequence, how they are supposed to deal with it and, importantly, that they are not alone in all of it. That’s also where strategy comes in again: as a clear roadmap that shows staff how they will be supported by a course of action and plan.

On top of that, it’s important to know – and plan and explain – what you will do as an organization in case something does go wrong because you have this duty to report data breaches within 72 hours.
Even if it’s just the first step, the awareness stage is very important. You can have the most solid security and information management systems to enhance personal data protection but as we know people are often the weakest link when it boils down to overall security and data protection. If an employee prints a list with sensitive personal data and, even by mistake, shares it with someone or if someone sends a file with Dropbox because it is too large for email you might already have a problem that isn’t covered by your solutions. Awareness is also a quick win and often doesn’t take more than a few workshops. Next, you start looking at the right tooling to support it all.
Risk analysis: from awareness and gaps to demonstrable GDPR compliance action
Would you say that properly completing this awareness stage is the most important one as it seems you already have quite some planning going on there?
Rick Gruijters: It is essential. However, from a GDPR perspective the second step is a bit more important. In that second stage, assessment and methodology, you first conduct a thorough risk analysis and look at everything: your people, your information management and other processes, your technologies and so forth. What do you have and what should you have? Where does information sit and where should it sit? Where are the main gaps and which gaps form the highest risk?
In a risk analysis you really can look at many things as the GDPR does impact many areas. Once you have identified all the parts that miss and all the gaps, whether it concerns processes, information management, people, technologies, security and so on, you build a matrix whereby you give a specific degree of risk to each missing piece.
In other words: you start prioritizing in a documented way. The matrix enables you to build a staged and, again, documented approach which leads to actions and projects to start, based upon risk factors.
Referring back to the fact that as an organization you’ll need to be able to show you did everything you possible could, if you aren’t “ready”, you can at least prove that you have started and have your plan in place to move forward. So, in my view the first stage of awareness and the second one of risk analysis combined are key steps you need to have taken when authorities start conducting controls soon.
On top of the fact that you started a project you can now show that 1) your staff has been educated and has started thinking about how to deal with information and 2) you have a documented plan that shows you know where you are, where you go and which actions you took and will take.
The third and final stage is the implementation stage where you effectively start the projects which you found in your analysis and defined in your plan. This also means that you’ll need to monitor and evaluate if what you wanted to achieve has been achieved, how you can optimize the project if needed and move on with the next project.
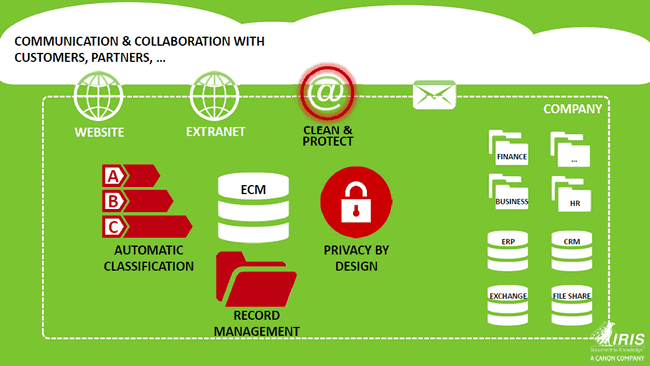
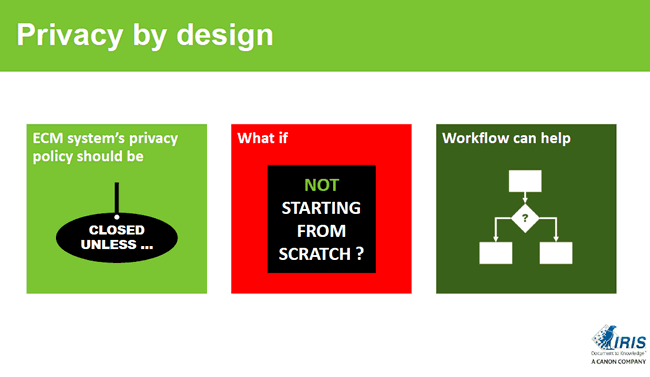
Privacy by design and information management in the GDPR: from ‘open unless to closed unless’
That’s clear. Time to dive deeper into enterprise information management and GDPR. You defined a few GDPR priorities from an Enterprise Information Management perspective when we talked earlier. Let’s take a look at each one. First, there is the GDPR’s privacy by design and what you call the migration from an ‘open unless’ to a ‘closed unless’ EIM/ECM approach. Can you explain?
Rick Gruijters: Privacy by design is indeed a key element of the GDPR and the regulation also says that systems and new applicators by default need to support it. In practice this means that your platforms, information management systems and others, at least need to be able to support a security model whereby only people who really need access to personal data, get it do their job.
If you look at ECM, where a lot of unstructured data is being managed however, you notice that traditionally many organizations used an ‘open unless’ implementation. This means that everything in the platform is open and everyone in the company can see everything with the exception of perhaps some folders such as the management or HR folder. Officially this ‘open unless’ model is often done in the spirit of transparency and enhancing collaboration. However, in practice we see that in several cases the reality is that everything is open because no one really knows what the security model is and so they don’t need to think about it.
That of course needs to change. You need to map your entire system and authorization structure and ask yourself if you know who has access to a specific folder today. In practice this is often not known so that’s the first thing to do: look at your authorization model and at the same time define how the new authorization model and security model in your ECM looks like, whereby with GDPR by default you close everything and grant access on a user permission and needs-based level. Hence: ‘closed unless’ instead of ‘open unless’. This is an interesting project for organizations to begin with. Moreover, it can be done relatively easily as they don’t need any software to do it: it’s a matter of rethinking and redesigning authorization.
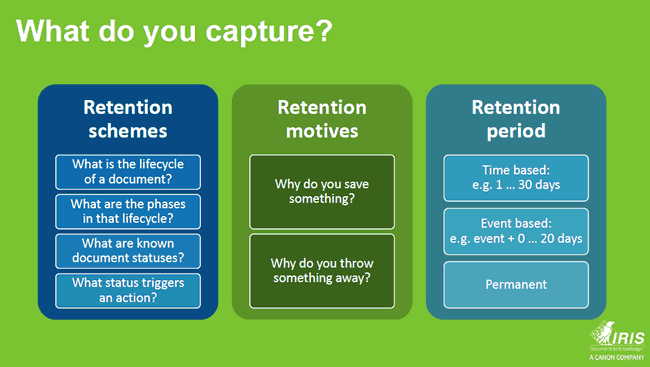
The right of erasure: GDPR, retention schemes and records management
The second one is the GDPR’s right of erasure which, from an information management perspective, includes the development of retention schemes to delete personal data.
Rick Gruijters: That brings us to records management. According to the GDPR, you shouldn’t retain information longer than necessary so that means you need to have a retention plan. Do you need to keep the information from a legal perspective, a business perspective, a historical viewpoint and so forth? If the answer is no, you could delete it. And if a data subject exercises his right of erasure, you need to be able to delete it.
You have documents that enter the organization and need to be retained for a specific period, invoices are an easy example. However, you also have documents or sets of documents that need to be erased, depending on a specific event. If someone leaves the company, after a while you need to delete the personnel file.
Another example: if a data subject goes to an insurer he needs to mention potential health issues. This could lead to a rejection of the insurance application. However, if that same person comes back to the insurer ten years later and in the meantime is entirely healthy, the insurance company might not refer to that health information as it is deleted.
You need to organize your records management in function of this. You need to draft a document classification model which looks at the types of documents and the retention schemes as defined by the law. In this case it’s national law as the GDPR lets the local legislator fill in that retention scheme.
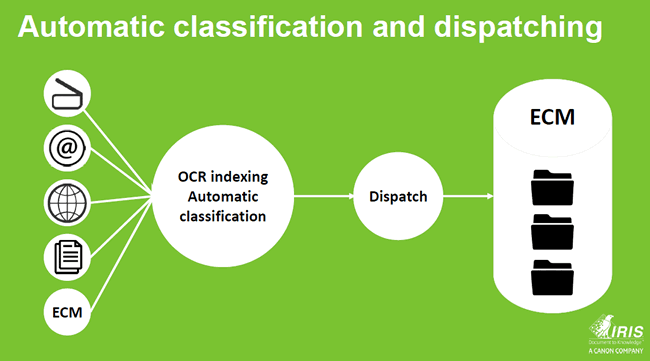
Taking information management to the next GDPR compliance level: automatic classification
That brings us to metadata as a must for the GDPR and for a retention scheme whereby automatic classification is important.
Rick Gruijters: Indeed. And it also brings us to the more interesting and intelligent solutions which are pretty innovative for many companies. Let’s take a step back: records management only works well if you have information about specific documents. The system needs to know what kind of document it is dealing with in order to be able to do something with it. In practice many users have a hard time to add information regarding a document. They just want to quickly store it and move on with their work. In other words: metadata are not properly filled in or added. You can say that a field is mandatory but still.
You can circumvent this issue by organizing it automatically with an engine, which is based on intelligent technology (AI) and can define ‘this is a payment slip’, ‘this is a job application’, you name it. On top of knowing what it is about, you can define the object type, extract metadata from the document and use all this information to put the document in the right place in the system and this way start organizing your records management better from the start.
This makes you information management system and environment richer and more complete. An additional benefit is that it gets easier to retrieve your document, don’t need to hassle the users of your systems and thus enhance efficiency and productivity.
If you have done all that you are really at privacy by design: the system is now secure on an authorization level, only those who need access have it and you know what is in the system and can be thrown out at the time it needs to be according to the GDPR.
Automatic classification beyond ECM: documents, data and PII across the full information landscape
Yet, then comes a big fear of organizations you said: knowing where everything sits at all times with all the other systems such as file sync and share (FSS) tools?
Rick Gruijters: Indeed. When the ECM organization is properly secured and managed, organizations remain confronted with the questions what information is still out there.
Automatic classification comes into the picture here as well. You can decide to not just classify your entire ECM environment but also your full information landscape, with the necessary monitoring. If the engine then detects that there is, for example, a job application document of a candidate on a file sharing system, it can pick it up and put it in the proper place within your ECM system.
You can take this a step further and not just classify your document type but also identify whether it contains Personally Identifiable Information (PII) and even about who because you can get the question from a data subject with regards to their personal data.
That is the deeper level where are able to define whether PII is involved or not, what type of PII it is (for instance, sensitive or ‘regular’) and to which individual it is related.
If you have done that, you are very close to a green light by the regulator in case of a potential control.
Top image: Shutterstock – Copyright: SB_photos – All other images are the property of IRIS Professional Solutions and their respective mentioned owners. Although the content of this article is thoroughly checked we are not liable for potential mistakes and advice you to seek assistance in preparing for GDPR. Disclaimer: i-SCOOP has been providing services to IRIS Professional Solutions.