
Big data and an abundance of information coming from multiple channels: two challenges facing every organization and offering plenty of opportunities if we know what data to capture how and what information to act upon to create business and customer value.
 We are overflowing with data but, what matters is data with purpose”. Time to bring artificial intelligence (AI) into the unstructured data and document capturing equation.
We are overflowing with data but, what matters is data with purpose”. Time to bring artificial intelligence (AI) into the unstructured data and document capturing equation.
In part one of this blog series, we looked at structured and semi-structured IDR (Intelligent Document Recognition), in part 2 we explained the triple challenge of unstructured information and concluded with the inability of document capturing systems to handle those challenges. In part 3, discover how fresh new technology can help you tame the Information Chaos / Big Data capture challenge explained in part 2. So now put your data scientist hat on, and let’s get to it!
Artificial intelligence: a new engine for a multitude of input sources and channels
Back in part 1 of this series, we learned about the Graphic-based and Rule-based methods and how they really won’t do a good job at extracting information from unstructured input, unless you severely reduce the variability of the input.
An example of a simplified input variability is to create an email inbox for vendors to send their invoices (i.e. invoice@abc.com), this way the semi-structured methods work well as IDR knows those are only invoices type.
However nowadays businesses should be able to IDR – that is extract relevant business information – from the full variety of emails coming in, like emails asking: where is my shipment, change my address, change quantity in order xyz, bill me on a different account, and 100’s of other topics. They should also be able to IDR all the other forms of text-based input communication channels, like social media, e-docs attachments, SMS text, web-chat, messaging and also paper (after OCR).
 To do this, you need a new engine – so let me introduce you to AI-based methods, where AI stands for Artificial Intelligence (pronounce A like in “able” and I like in “time”).
To do this, you need a new engine – so let me introduce you to AI-based methods, where AI stands for Artificial Intelligence (pronounce A like in “able” and I like in “time”).
Different forms of artificial intelligence for Intelligent Document Recognition
Semantic understanding
The first AI-based method we will review is Semantic Understanding; IDR engine will use it for data extraction.
Semantic Understanding uses a linguistic approach to make sense of the text and locate key content in the email text body. For example, if it finds the phrase “I don’t want to cancel the contract”, it applies linguistic intelligence and recognises the whole sense of the communication and understands it is about a contract non-cancellation. In contrast, a rule based system would only pick up the word ‘cancel’ and understand Cancel Contract and then act on it contrary to the customer’s wishes. This is great stuff, also used by SIRI, Google NOW and the likes.
Statistical clustering
A second AI-based method is the statistical clustering algorithm an IDR engine will use to categorize documents. This science is part of the AI Machine Learning field where IDR can recognize the document type (we also call this “classification”): this is an invoice, this is a proof-of-payment, this is a proof-of-income, this is a cancellation note, etc. For instance, in the mortgage document example of part 1, we can have about 160 different document types.
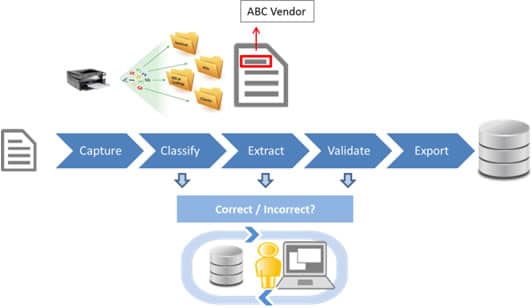
But first, before you can run this AI-based classification engine, you need to train it. To do so, you feed the algorithm a “training-set”, a group of documents that belong to the same class. Then the algorithm analyzes the text in the training-set and, out of the millions of possibilities of word combinations, it uses the statistical clustering method to define the unique text-based features for that class. This results into an AI Model. And – this is done without human intervention, very important, as in most case, a human will not find those unique features!
Different algorithms and self-learning
Once the classification engine is trained, the AI Model is applied to new incoming documents and it classifies them based on its learning. It recognizes the document type automatically and unsupervised, sending the unknown to an exception queue to be processed by a human expert operator.
Below you see a number of those algorithms, like SVM, Bayes and Neural-Net. Each algorithm has its strength and weakness and some advanced classification scheme actually use a combination of those algorithms to make a better decision.
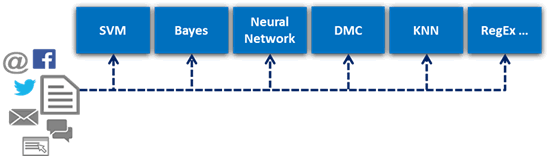
In the capture workflow, the unrecognized documents sent to human correction will also translate, over time, into new AI-Model learning. This is the Self-Learning mechanism. With those techniques, an IDR solution classifying unstructured content can yield an estimated 80% optimization rate!
Intelligent Document Recognition and Artificial Intelligence: the benefits
In summary, here are the benefits offered by Intelligent Document Recognition (IDR) powered by Artificial Intelligence:
- The ability to learn to understand the true meaning of any type of text based input, regardless of structure, source, and format
- Automatically learn over time from expert exception handling and therefore offers flexibility
- Automate and improve business processes in mailroom, back office and contact center
In a next post, I cover additional benefits, related to building a knowledge-base and automating the response to the text-based inputs to tackle the response time challenge (increasingly real-time)… check it out.
The author, Roland Simonis has over 20 years of ECM Capture experience, is the author of multiple white papers and a regular speaker at ECM and SharePoint conferences.





