Imagine trying to learn a complex new skill, like playing golf or solving a Rubik’s Cube, but the only feedback you ever get is a simple “yes” or “no” after you finish. You aren’t told what you did wrong, only that you failed. This is the frustrating reality for many Artificial Intelligence models trained via traditional Reinforcement Learning (RL). They rely on trial and error, flailing in the dark until they stumble upon a solution.
But what if AI could learn the way humans do? When we fail, we don’t just reset; we pause, reflect on what went wrong, conceptualize a better strategy, and try again. This cycle of experience and reflection is the heartbeat of human learning.
Enter Experiential Reinforcement Learning (ERL). This emerging training paradigm is shifting the landscape of how Large Language Models (LLMs) evolve from static text generators into dynamic, decision-making agents. By embedding a cycle of experience, reflection, and consolidation directly into the training loop, ERL allows models to essentially “think” about their mistakes and internalize the lessons, leading to dramatic improvements in reasoning and problem-solving capabilities.
The Problem with Traditional Trial-and-Error
To understand why Experiential Reinforcement Learning is such a significant leap forward, we first need to look at the limitations of the current standard: Reinforcement Learning with Verifiable Rewards (RLVR). In this traditional setup, an AI agent takes actions in an environment and receives a reward—usually a scalar signal like +1 for success or 0 for failure.
While this works for simple tasks, it hits a bottleneck in complex, multi-step reasoning problems. In these scenarios, rewards are often sparse and delayed. The model might make twenty decisions in a row, and only at the very end does it find out it failed. The challenge is “credit assignment”: the model has no idea which of those twenty decisions caused the failure. Was it the first step? The last one? A combination of both?
Standard RL forces the model to implicitly infer these connections through thousands of repetitive attempts. It is an inefficient process of blind exploration, hoping to stumble upon the right path enough times to learn the pattern. It lacks the explicit reasoning mechanism to say, “I failed because I turned left instead of right at the second intersection.”
What is Experiential Reinforcement Learning?
Experiential Reinforcement Learning changes the game by treating “experience” not just as a stream of data, but as a source of structured wisdom. It draws inspiration from human cognitive theories, specifically Kolb’s experiential learning cycle, which posits that effective learning comes from a loop of experience, reflection, conceptualization, and experimentation.
In the context of AI, ERL embeds an explicit experience–reflection–consolidation loop inside the reinforcement learning process. Instead of just optimizing for a score, the model is trained to analyze its own behavior. It transforms raw, binary feedback (pass/fail) into rich, linguistic reasoning signals.
The core philosophy here is that an intelligent agent shouldn’t just memorize which actions lead to rewards; it should understand the mechanics of its success and failure. By generating a “reflection”—a text-based critique of its own attempt—the model creates a bridge between a failed attempt and a successful one.
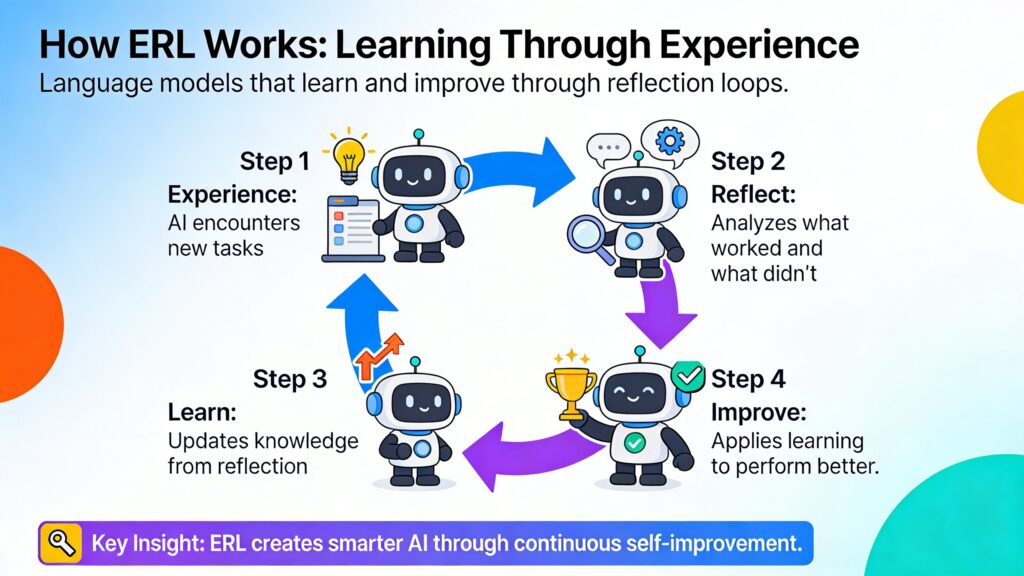
How ERL Works: The Three-Step Loop
The architecture of Experiential Reinforcement Learning is elegant in its logic. It breaks down the learning process into distinct phases that mimic a coaching session, where the model acts as both the player and the coach.
1. Experience and Feedback
The process begins with the model making an initial attempt at a task given a specific input or prompt. This could be solving a math problem, navigating a digital grid, or answering a multi-hop question. The environment evaluates this attempt and provides feedback (success or failure).
2. Reflection and Refinement
This is where ERL diverges from standard methods. If the initial attempt fails (or falls below a certain reward threshold), the model triggers a reflection phase. It generates a self-critique, analyzing the feedback and its own previous actions to determine what went wrong. It asks itself: “Why did this fail?” and “What should I do differently?”
Guided by this self-generated reflection, the model makes a second attempt. Because this second attempt is conditioned on the specific advice generated during the reflection, it is significantly more likely to succeed. The model effectively “debugs” its own reasoning in real-time.
3. Consolidation and Internalization
While reflection is powerful, it is also computationally expensive. We don’t want an AI that needs to stop and write a diary entry every time it answers a question in the real world. We want an AI that has internalized the lesson.
This is the “consolidation” step. ERL uses a technique called selective distillation. Once the model successfully solves the problem using its reflection, it updates its base policy (its core “instincts”) to mimic that successful behavior without needing the reflection step. It trains the model to go straight from the problem to the correct solution, effectively bypassing the need for the intermediate reasoning step in the future.
This ensures that the gains made during training are durable and available at deployment time without the additional inference cost of generating reflections.
The Role of Memory and Gating
Two critical mechanisms make this system robust: Gated Reflection and Cross-Episode Memory.
Gated Reflection ensures efficiency. The model doesn’t reflect on every single action. If it solves a problem correctly on the first try, it moves on. Reflection is triggered only when the reward is low. This mimics human attention; we don’t analyze how we tie our shoes every morning, but we definitely analyze our swing if we miss the golf ball. This focuses the model’s computational power on the trajectories that actually need improvement.
Cross-Episode Memory allows the model to maintain a “journal” of successful strategies. If a specific type of reflection helped solve a puzzle in the past, that insight is stored. When the model encounters a similar problem later, it can retrieve that past reflection to guide its new attempt. This prevents the model from making the same mistakes over and over again across different episodes, turning local corrections into global wisdom.
Impact on Performance: The Numbers
The theoretical benefits of Experiential Reinforcement Learning are backed by impressive empirical results. When tested against strong baselines like standard RLVR, ERL consistently comes out on top, particularly in environments where reasoning and planning are essential.
- Complex Control Tasks: In environments like Sokoban (a puzzle game where you push boxes to specific locations), ERL achieved performance gains of up to +81%. Sokoban is notoriously difficult for AI because one wrong move can make the puzzle unsolvable. ERL’s ability to reflect on “stuck” states allows it to learn recovery strategies that standard RL misses.
- Sparse Reward Navigation: In tasks like FrozenLake, where an agent must navigate a grid without falling into holes, ERL showed improvements of around +27%. The reflection mechanism helps the agent understand the dynamics of the environment (e.g., “stepping here leads to a hole”) much faster than random exploration.
- Agentic Reasoning: In text-based reasoning tasks like HotpotQA, which requires using tools and retrieving information to answer questions, ERL improved performance by up to +11%. This suggests that the benefits of experiential learning extend beyond simple games into complex, real-world language tasks.
Crucially, these improvements aren’t just about getting a higher score; they are about learning efficiency. ERL agents reach high-performance levels faster than their counterparts because they aren’t wasting time on undirected exploration. Every failure becomes a lesson, accelerating the optimization curve.
Beyond “Reward Hacking”
One of the persistent dangers in reinforcement learning is “reward hacking,” where an agent finds a loophole to get a high score without actually solving the task as intended (e.g., a vacuum robot that dumps dust just to pick it up again). By grounding the learning process in structured reflection, ERL mitigates this risk.
Because the model must articulate why it is changing its behavior, the learning process becomes more transparent and aligned with the task’s true objective. The reflection acts as an intermediate reasoning signal that keeps the agent on track. Furthermore, by internalizing these reflections, the model develops a robust policy that is less reliant on superficial shortcuts and more focused on the underlying logic of the task.
The Future of Self-Taught AI
Experiential Reinforcement Learning represents a shift from learning from feedback to learning from experience. It acknowledges that data isn’t just what happens to an agent; it’s how the agent interprets what happened.
As we look toward the future of Artificial Intelligence, the ability for models to self-correct and self-improve without constant human hand-holding is paramount. We are moving away from the era of purely supervised fine-tuning, where models simply imitate human examples, toward an era of autonomous agents that can navigate novel environments, encounter failure, and emerge smarter on the other side.
By embedding the human-like loop of experience, reflection, and consolidation into the heart of AI training, ERL provides a practical, scalable mechanism for transforming fleeting feedback into durable behavioral improvement. It is a stepping stone toward AI that doesn’t just follow instructions, but truly learns from its own journey.